Summary
This note presents results of performance measurements on mass data loading into the traditional database platform SQL Server and the accounting cloud platform Exact Online. It compares various strategies and their impact on usability and performance.
Invantive UniversalSQL at this moment is capable of moving large volumes of relational data across cloud and database platforms.
Invantive UniversalSQL peak performance on loading data into Exact Online is estimated at 40.000 transactions per hour for a single company and 200.000 transactions per hour across many companies.
For Exact Online with Invantive UniversalSQL, it is notable that data load performance of the REST API is still inferior compared to the performance to the XML API by 50% when using bulk insert and factor 3 when using REST normal insert.
The XML API is despite it’s age the preferred API to use in combination with Invantive UniversalSQL for mass loading data into one company. Due to missing parallel requests support on XML, the bulk insert is the preferred way for loading data across multiple companies.
Exact Online resembles a MPP-structure like Teradata, scaling poorly per partition but scaling great across partitions up to a parallelism degree between 8 and 10. Typically, Exact Online throughput with Invantive UniversalSQL is determined by Exact Online and not the amount of computation power at the Invantive UniversalSQL node.
The API Gateway is not yet in use. Might the API Gateway be activated, the use of bulk insert is preferred, since it reduces the number of API calls by a factor of 250 compared to insert on REST tables.
For a dedicated entry-level SQL Server instance, the throughput levels are two or three levels of magnitude higher than for a cloud platform when using bulk insert on Invantive UniversalSQL. Bulk insert adds at least one level of magnitude performance to normal insert on SQL Server, but CPU power on the loading server also becomes a factor of importance with this type of throughput.
Invantive UniversalSQL peak performance with entry-level SQL Server instances exceeds millions transactions per hour is easily feasible.
The amount of CPU power needed on the loading server increases with the amount of data processed per hour. For a throughput of over 10 million rows per hour use a multi-core server. Memory use of Invantive UniversalSQL has become excellent with recent advances.
And to answer the question from title: Invantive UniversalSQL in it’s current conception does not yet allow crossing interstellar distances in close to nothing. Infinite Probability Drive as introduced by Douglas Adams in the Hitchhiker’s Guide to the Galaxy remains the vehicle of choice for interstellar travel.
Important Update December 2019
Starting December 2019 OData batch requests have been desupported on Exact Online. All existing uses within Invantive UniversalSQL such as ‘bulk insert’ will automatically fallback to non-batched versions starting release 17.32.127 and 17.33.217 (BETA).
Therefore, the recommendation is to use XML imports instead of REST API for loading data.
Invantive UniversalSQL
Invantive UniversalSQL is an advanced SQL engine which relies on 3rd party data containers for storing and retrieving data. Besides an integrated session-specific in-memory database it provides no storage facilities. However, over 50 back-end data container platforms are supported by “providers”, including traditional databases such as DB2 or Oracle, files such as JSON or audit files and cloud-platforms such as Teamleader, Exact Online and Visma.
A global database spanning many data containers while still enforcing data security and integrity.
One or multiple data containers can be used at the same time within one SQL statement and one definition of SQL semantics, effectively eliminating the need for extensive ETL-coding and spending time connecting and understanding API’s.
Although the ultimate capabilities are determined by the chosen data containers, Invantive UniversalSQL unifies and simplifies data retrieval and storage across an ever-growing list of data container platforms. This allows configuration and use of a global database spanning many data containers while still enforcing data security and integrity.
The SQL grammar of Invantive UniversalSQL has grown over the years to a unite of all familiar database platform syntaxes plus ANSI SQL. This merged grammar has been extended with a number of Invantive-specific extensions, especially in the area of compliance and ease of use.
Goal
Invantive UniversalSQL’s initial releases only supported data retrieval and were mostly used for reporting, consolidation and analysis purposes. Over the years, the creation, update and deletion of data has been added and is available where supported by the individual data container platforms and providers. With the growing use of Invantive UniversalSQL as a replacement for ETL-tools to exchange data, bulk data loading features have been added to various drivers.
Goal of this post is:
Establish the current throughput is of Invantive UniversalSQL using entry-level devices on the SQL Server database and Exact Online database for a variety of common workloads.
Common workloads have been defined as:
- Load one hundred thousand customers into a single partition (database) on SQL Server.
- Load ten thousand customers into a single partition (company) on Exact Online.
- Load one hundred customers into 100 partitions each for a total of 10.000 loaded customers (Exact Online only).
A “partition” is defined within Invantive UniversalSQL as follows:
Especially online platforms have a multi-tenant structure, in which the data is partitioned per customer, company or person. When the data model is identical across tenants, Invantive UniversalSQL considers them ‘partitions’. SQL statements can run across multiple or one partitions, often in parallel. This enables consolidation scenarios across partitions (such as Exact Online or Nmbrs companies) as well as high-performance in MPP environments.
The partitions to be used can be specified with the ‘use’ statement, either through an explicit list of partitions to be selected across data containers, or through a SQL select statement returning the list of partitions to use. Please note that although the ‘use’ statement resembles the ‘use DATABASE’ statement on Microsoft SQL Server or PostgreSQL you can on Invantive UniversalSQL have multiple partitions active at the same time in one user session.
Setup
The measurement was set up using entry-level configurations on AWS low-cost burstable instance classes:
- SQL Server Express Edition, t2.small class: 1 vCPU, 2 GB memory, bursts in CPU and IOPS.
- Windows 2016, t2.small class: 1 vCPU, 2 GB memory, bursts in CPU and IOPS.
The AWS location is Ireland and SQL Server and Windows 2016 were on the same VPC. For Exact Online, the Dutch environment was chosen and used on a Sunday morning. All inter-connections are low-latency, high throughput but also considered mainstream network configurations in the Dutch market.
The addition of additional resources in terms of disk throughput and CPU has been found beneficial in the past for large volumes being loaded continuously. For instance, larger sites running Data Replicator across thousands of Exact Online companies typically use Azure SQL Server instances of type S6.
The instances for the test have been chosen such to represent normal limited data volumes loaded per day using a burstable instance. For instance, AWS’ t2.small on SQL Server allows 300 CPU credits for bursting (1 CPU credit = 1 CPU minute at 100%) and up to 3.000 IOPS for a limited time. In general, we recommend the use of AWS as a cloud platform since AWS makes explicit the amount of resources granted while Microsoft Azure does it’s best not to tell you what you get in terms of resources.
The t2.small class of the Windows 2016 server is the minimum requirements; Invantive products won’t run on t2.nano or t2.micro due to minimum memory requirements enforced during installation.
We recommend the use of AWS as a cloud platform.
Invantive UniversalSQL version 17.23.52 was used, bundled with a non-debugging version of Invantive Query Tool 17.23.49.
Providers were left at it’s default settings, unless explicitly specified in the scenarios.
The test set of customers was created by taking company data from the Chamber of Commerce using Invantive UniversalSQL. The test set was loaded into in-memory storage of Invantive UniversalSQL to minimize latency when retrieving the data for uploading to SQL Server and Exact Online.
Loading was done on SQL Server using a number of scenarios:
- SI1: Row-by-row using the ‘insert’ statement with parallel left at 1.
- SB1: Bulk using the ‘bulk insert’ statement of Invantive UniversalSQL with parallel left at 1.
Loading was done on Exact Online using:
- EI1: Row-by-row through the REST API using the ‘insert’ statement with parallel left at 1.
- EB1: Bulk through the REST API using the ‘bulk insert’ statement of Invantive UniversalSQL with parallel left at 1.
- EX1: Bulk through the XML API using the ‘insert into uploadxmltopics’ statement of Invantive UniversalSQL with parallel at 1.
- EI10: Row-by-row through the REST API using the ‘insert’ statement with parallel at 10.
- EB10: Bulk through the REST API using the ‘bulk insert’ statement of Invantive UniversalSQL with parallel at 10.
- EX10: Bulk through the XML API using the ‘insert into uploadxmltopics’ statement of Invantive UniversalSQL with parallel at 10.
- EB32: Bulk through the REST API using the ‘bulk insert’ statement of Invantive UniversalSQL with parallel at 32 (added when parallel 10 reflected near linear scaling).
- EB100: Bulk through the REST API using the ‘bulk insert’ statement of Invantive UniversalSQL with parallel at 100 (added when parallel 10 reflected near linear scaling).
Insert on SQL Server starts and ends a transaction which does one insert. Bulk insert on SQL Server uses the bulk copy features default available in the SQL Server ADO.NET driver. Insert on Exact Online REST execute a single HTTP POST-request; bulk insert on Exact Online REST executes a batched ($batch) HTTP request and uploadxmltopics uses the native XML API with a light wrapper to split payload in smaller parts to circumvent scenarios in which the XML upload crashes due to excessive load at Exact Online.
The script used to measure performance is available on GitLab.
Measurements
The following table lists the measurements made:
| Scenario | Platform | SQL Statement | Parallel | #Partitions | #Customers | #Calls | Run 1 | Run 2 | Run 3 | Throughput (#/hour) |
|---|---|---|---|---|---|---|---|---|---|---|
| SI1 | SQL Server | insert | 1 | 1 | 10.000 | 10.000 | 0:24 | 0:25 | 0:24 | 1.500.000 |
| SB1 | SQL Server | bulk insert | 1 | 1 | 10.000 | 1 | 0:04 | 0:05 | 0:04 | 8.300.000 |
| EI1 | Exact Online REST | insert | 1 | 1 | 1.000 | 1.000 | 4:27 | 4:21 | 5:00 | 13.043 |
| EB1 | Exact Online REST | bulk insert | 1 | 1 | 1.000 | 4 | 2:28 | 1:48 | 2:17 | 27.481 |
| EX1 | Exact Online XML | uploadxmltopics | 1 | 1 | 1.000 | 11 | 1:51 | 1:09 | 1:36 | 39.130 |
| EI10 | Exact Online REST | insert | 10 | 100 | 10.000 | 10.000 | Unknown | Unknown | Unknown | Unknown |
| EB10 | Exact Online REST | bulk insert | 10 | 100 | 10.000 | 400 | 2:48 | 2:55 | 3:01 | 204.933 |
| EX10 | Exact Online XML | uploadxmltopics | 10 | 100 | 10.000 | 1.100 | Unknown | Unknown | Unknown | Unknown |
| EB32 | Exact Online REST | bulk insert | 32 | 100 | 10.000 | 400 | 3:18 | 2:59 | 3:02 | 193.202 |
| EB100 | Exact Online REST | bulk insert | 100 | 100 | 10.000 | 400 | 2:49 | 3:28 | 3:12 | 189.806 |
Note 1: during Exact Online loading, the average CPU load on the Windows server was below 10%, even with 10 parallel requests executing. Memory allocated to the 64-bit Query Tool was in range of 400-600 MB. Memory allocated before logging in was approximately 220 MB.
Note 2: during loading data into SQL Server, the average CPU on the Windows was 40% for normal insert, 100% for bulk insert and on SQL Server was around 10%.
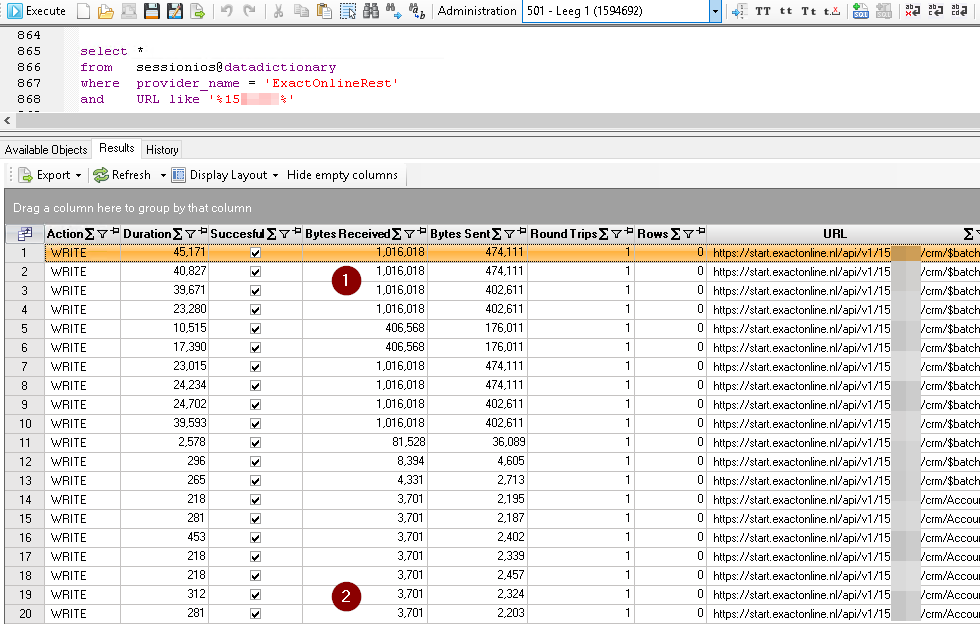
Note 3: during SQL Server bulk insert, the overhead of Invantive UniversalSQL was notable. According to session I/Os, the actual upload time into SQL Server was between 1.227 and 1.640 ms for 10.000 rows (12 MB).
Note 4: Exact Online session I/Os have also been studied, such as in the picture below where stands for 250 batched inserts into Exact Online and for non-batched inserts:
Discussion
Unexpected Events
During the collection of the measurements a number of unexpected events have been found:
-
The XML API seemed to vary widely in performance, but we discovered that the performance of XML API is even higher when loading identical or slightly changed data sets. The tests have been extended to ensure that all records are considered new to ensure comparing apples with apples. Upload times for incremental loading of 1.000 unchanged customers are in the 20-30 seconds range, as opposed to close to two minutes for loading 1.000 totally new customers.
-
The insert and XML upload operation across 100 partitions on Exact Online ran serial instead of parallel. It was found that only bulk insert also optimization across multiple parallel requests. Loading across multiple partitions is not often found, but since Invantive UniversalSQL is most often used in combination with Exact Online an enhancement has been requested.
General
The amount of CPU power needed on the loading server increases with the amount of data processed per hour; on SQL Server bulk insert we’ve seen a CPU load approaching 100% for a short time frame. The loading server CPU remained cool when loading Exact Online at it’s peak speed but with a 40-times slower throughput than SQL Server. For loading more than 10 million rows per hour, please use a multi-core server.
Memory use of Invantive UniversalSQL has become excellent with recent advances in compression, de-duplication and re-use of memory. Even when continuously and in parallel transporting large result sets, the memory footprint stood well below 1 GB during the tests. Based upon these results, the required minimum physical memory has been decreased from 1,5 GB to 1 GB for all products except Invantive Control. Invantive Control requirements have been reduced from 3 GB to 2 GB.
Exact Online
For Exact Online, it is notable that data load performance of the REST API is still inferior compared to the performance to the XML API by 50% when using bulk insert and factor 3 when using REST normal insert. The XML API is despite it’s age the preferred API to use in combination with Invantive UniversalSQL for mass loading data into one company.
Of the Exact Online APIs used, only XML API had a throttle in place during the tests, limiting call rate to 60 calls per 65 seconds. The XML throttle of 1 call per second however was never reached or approached; the payload was distributed across 11 HTTP calls in several minutes. The API Gateway is not yet in use, and it is unclear whether it will be activated. However, even when never activated the both insert and bulk insert use of the REST API are outperformed by the XML API.
Might the API Gateway be activated, the use of bulk insert is preferred, since it reduces the number of API calls by a factor of 250 compared to insert on REST tables.
The load on the Windows server was very low throughout the tests, indicating that the throughput is determined by the throughput of Exact Online.
Exact Online resembles a MPP-structure like Teradata’s vAMPs, scaling in partitions: increasing data volumes per partition translates directly into increased load times. But parallelizing across partitions and loaders, the throughput increases dramatically: from 1 partition with an hourly throughput of 27.481 customers through bulk insert on the REST API to 100 partitions with 10 parallel loads and a hourly throughput of 204.933 customers.
Exact Online bulk insert throughput seems to rapidly grow with increasing parallelism but levels off above 10 parallel loaders as set by ‘set requests-parallel-max 10’. Using more parallel loaders does not increase total throughput. The ratio between 204.933 and 27.481 is 7.5, so the maximum sensible degree of parallelism for data loading is probably somewhere between 8 and 10.
SQL Server
For a dedicated entry-level SQL Server instance, the throughput levels are two or three levels of magnitude higher than for a cloud platform when using bulk insert on Invantive UniversalSQL. Invantive UniversalSQL’s bulk insert adds at least one level of magnitude performance to normal insert on SQL Server, but CPU power on the loading server also becomes a factor of importance with this type of throughput.
A peak performance with entry-level SQL Server instances loading millions transactions per hour is easily feasible with Invantive UniversalSQL.
It is to be expected that the 1.000-fold performance and scalability gain of Data Replicator after replicating cloud platforms such as Exact Online holds also for data loading: one SQL Server instance can load data in parallel from 1.000 sources across the Internet, given sufficient CPU power at the Data Replicator server.
In the same way, a small database instance can easily load tens or hundreds of millions webhook events per day as received by Invantive Data Replicator from Exact Online and others, given sufficient CPU minutes. Even when receiving over 1.000 webhook events er second, the loading by Invantive UniversalSQL into SQL Server does not pose a performance issue.