Invantive Cloud enables users to import data from cloud data sources into Power BI Desktop, Power BI service, Power Query, Azure Data Factory and Microsoft Integration Services. All downloads are available using OData version 4. The OData4 protocol is interpreted by Invantive Cloud, optimized using Invantive SQL and executed using the native protocol of the cloud data sources, irrespective whether that is SOAP/WSDL, XML, REST, JSON or a custom protocol.
Before continuing, make sure to understand the structure of Invantive Cloud. The structure is described on Invantive Cloud Structure. An overview of actionable performance optimization techniques and techniques to reduce download size are given on Overview of Power BI Performance and Download Size Improvement Techniques.
Download Size Limits
Invantive Cloud provides a shared service for reporting, analysis and data exchange. To ensure proper operations and acceptable costs, limits are posed on the actual use. Excessive amounts of data downloaded reduce the effectiveness of the platform and require more time to process on for instance the Power BI service. Various other techniques to reduce the total amount of downloads across a calendar day, as well as techniques to reduce the download size of an individual data set are presented in the overview.
As explained in the section “Measurement”, limiting the number of columns for which data is retrieved can decrease (compressed) download size by a factor 3. Higher and lower factors are possible, depending on the properties of the data. The uncompressed data volume was found to be decreasable by a factor 16, yielding measurable reduction of the Microsoft Power BI processing time.
To exclude columns from your data set in Power BI Desktop:
- Select a Power BI dataset.
- Go to the Power Query Editor.
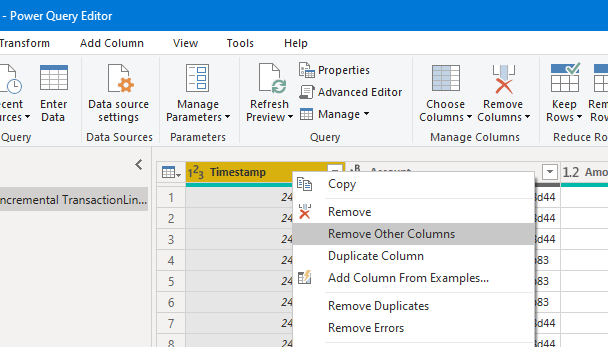
- In the Power Query editor: select any column you wish to keep.
- Select “Remove Other Columns”:
- Go to the applied steps.
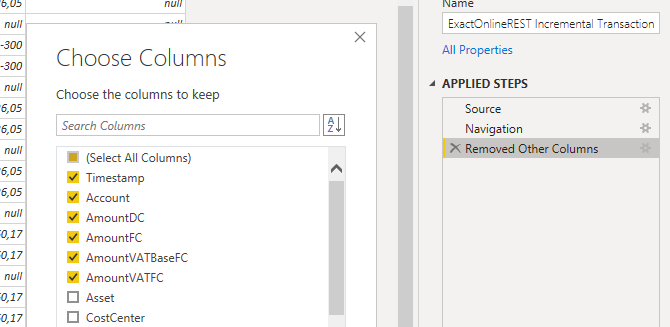
- Select the “gear” symbol next to “Removed Other Columns”.
- Check all columns to keep:
- Have the Power Query engine apply the changes to your Power BI report.
Measurement
To measure the impact of solely selecting the needed columns, a test case was prepared using financial data from approximately 200 small test companies on Exact Onlineusing the table TransactionLinesIncremental. The table TransactionLinesIncremental contains approximately 215.000 Exact Online journal entry lines. The data distribution is similar to that of other data sources for financial control.
All tests were executed twice to allow the data to load in the OData4 cache before serving them to Power BI.
Full Data Set
The full data set contains 48 columns, partially sparsely populated, and generates the following OData4 request for the table:
/SEGMENT/odata4/ExactOnlineREST.Incremental.TransactionLinesIncremental@eol
The associated Power BI query is:
let
Source = OData.Feed("https://bridge-online.cloud/SEGMENT/odata4", null, [Implementation="2.0"]),
#"ExactOnlineREST.Incremental.TransactionLinesIncremental@eol_table" = Source{[Name="ExactOnlineREST.Incremental.TransactionLinesIncremental@eol",Signature="table"]}[Data]
in
#"ExactOnlineREST.Incremental.TransactionLinesIncremental@eol_table"
The full data set used in the test has a network size of 15 MB (15,044,436 bytes to be exact, compressed) and an uncompressed size of 244.815 KB. The data set was downloaded from the Invantive Bridge Online OData cache in approximately 27 seconds by Power BI on a high-performance HP workstation, including processing, over a 250 Mb link.
Previous measurements on Invantive Bridge Online have shown that the cumulative throughput can easily exceed 5 Gb, so Power BI Desktop seems to be the limiting factor in processing the 244 MB of JSON data transported through OData.
A separate test was run to establish whether Power BI was indeed the limiting factor. The following statement was executed to simulate the download:
curl --user john.doe@acme.com:secret https://bridge-online.cloud/SEGMENT/odata4/ExactOnlineREST.Incremental.TransactionLinesIncremental@eol --output c:\temp\null.json
The download of 244 MB using curl takes consistently 14 seconds, which is sufficient to saturate a 140 Mb network link. Instead Power BI seems to be the slowest link in the chain.
The content resembles:

Data Set with solely Timestamp
Using the step “Remove Other Columns”, all columns except Timestamp were removed.
Downloading the new data set in Power BI used a more restricted OData4 request:
/SEGMENT/odata4/ExactOnlineREST.Incremental.TransactionLinesIncremental@eol?$select=ID%2CTimestamp
The request also includes the ID column, which is deemed necessary by Power BI Desktop.
The associated query is:
let
Source = OData.Feed("https://bridge-online.cloud/SEGMENT/odata4", null, [Implementation="2.0"]),
#"ExactOnlineREST.Incremental.TransactionLinesIncremental@eol_table" = Source{[Name="ExactOnlineREST.Incremental.TransactionLinesIncremental@eol",Signature="table"]}[Data],
#"Removed Other Columns" = Table.SelectColumns(#"ExactOnlineREST.Incremental.TransactionLinesIncremental@eol_table",{"Timestamp"})
in
#"Removed Other Columns"
The download size of this data set with solely the ID and Timestamp columns is 5 MB (5,571,914 bytes to be exact, compressed) and - according to Power BI - an uncompressed size of 14.669 KB. The data set was downloaded from the Bridge Online cache in approximately 6 seconds.
The content resembles:

Discussion
Limiting the number of columns downloaded into Power BI to the bare minimum reduced the download size on-the-wire by a factor 3; the download size uncompressed was reduced by a factor of over 16.
There is no superfluous data in the limited width download. The uniqueness of the data fetched limits the compression ratio. Nonetheless, reducing the number of columns fetched can reduce the data volume sufficiently to apply this technique, especially when the content skipped is little compressible.