Breaking Changes
Exact has applied several unplanned breaking changes since December 2020. Deployment of more breaking changes is scheduled to take place on July 1. The impact of these changes to the Exact Online API ecosystem can not be foreseen nor tested currently.
To make sure the largest percentage of deployments keeps running Invantive has announced to discontinue support on the on-premise products Invantive Data Hub and Data Replicator in combination with Exact Online per July 1, 2021. This eases resource allocation to the products with the largest user communities and fastest routes to deployment. The support on Data Hub and/or Data Replicator with other (cloud)platforms remains unchanged.
As an aid to existing users, some workarounds will be presented as wikis for common deployment scenarios of the on-premise products Invantive Data Hub and Invantive Data Replicator. All these workarounds assume that Invantive Cloud will have limited downtime. Invantive Cloud has been ranked on priority 1 to keep running, closely followed by the large user group on Invantive Control for Excel.
These workarounds will apply to users running workloads for at most 50 Exact Online companies. Currently, there are no workarounds for higher volumes of companies.
Download Exact Online data to save in SQL Server on-premise
A popular application of Invantive Cloud is to act as an OData producer for Azure Data Factory. This enables the replication of Exact Online transaction data, JIRA Service Desk, or ActiveCampaign into SQL Server or other data flows. This also works for all other supported platforms as a data source. For some background please consult:
- Hoe verbind ik Exact Online met Azure Data Factory?
- Retrieve a specific Exact Online OData4 data set using Azure Data Factory
However, Invantive Cloud can not access on-premise resources such as an on-premise Microsoft SQL Server environment. The traditional implementation is to use Invantive Data Hub to directly connect to both the Exact Online data source and SQL Server data source. Then use either bulk copy SQL statements or Data Replicator to store the Exact Online data in SQL Server. Some samples of this deployment are:
By downloading data from Invantive Cloud into an on-premise Data Hub or Data Replicator process you can still receive the Exact Online data and store them in a local Microsoft SQL Server environment. Of course, it is also possible to save the Exact Online data in Microsoft SQL Server on Azure, but Azure SQL Server can also be accessed directly from Invantive Cloud so a more simple approach should be used.
The data flow from the Exact Online data source to the target is as follows:
- Exact Online API servers
- Invantive Bridge Online with Exact Online driver
- Invantive Data Hub with Invantive Bridge Online driver
- Invantive Data Hub with Microsoft SQL Server driver.
The same data flow applies for other sources such as by replacing (1) with the Chargebee API servers and using the Chargebee driver of Invantive with (2).
The set up of receiving data from the Exact Online data source into an on-premise Microsoft SQL Server database through Invantive Cloud consists of the following steps:
- Define a virtual Exact Online database on Invantive Cloud.
- Define a virtual database on Invantive Data Hub with the Bridge Online and Microsoft SQL Server drivers.
- Use Invantive SQL statements to copy, replicate or synchronize the data.
Pre-requisites
Make sure to use Invantive Query Tool and Invantive Data Hub in release 20.0.148 or newer, or 20.1.380 BETA or newer.
Define Exact Online database on Invantive Cloud
The virtual Exact Online database can be configured by following the already documented steps on Invantive Cloud up to “Configure Power BI for Exact Online”.
It is assumed for the next steps that the Invantive Cloud user is ‘john.doe@acme.com’ with password ‘secret’. The download will take place using Invantive Bridge Online and the database has Database URL Segment ‘acme-exact-online’:
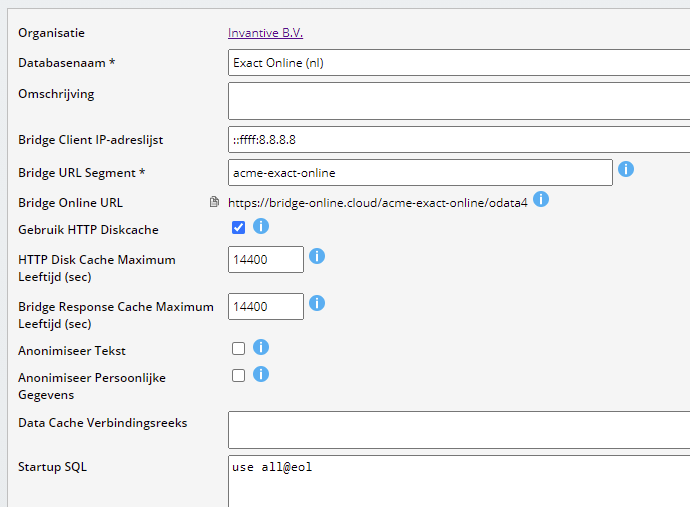
The startup SQL depicted selects all companies made available. Make sure to allow access from your devices by whitelisting the Internet IP address in the Bridge Client IP-address list.
Define a virtual database on Invantive Data Hub
The first step is to check connectivity by starting the Invantive Query Tool. Go to the database group “Various” and choose the “Invantive Bridge Online” database. Log on as shown:
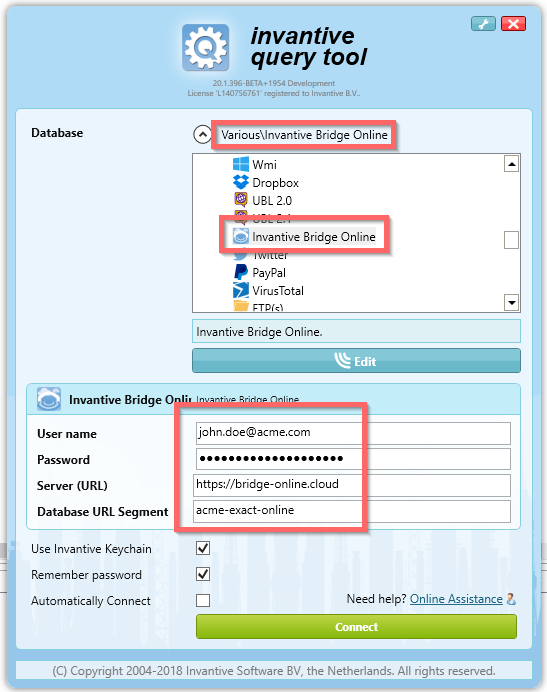
Upon connection, the Bridge Online driver will establish the metadata for the Invantive Cloud database. In this case, this will resemble the standard Exact Online catalogs:
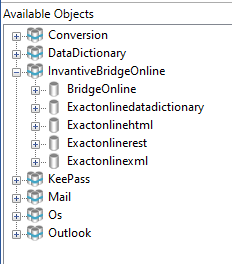
with the addition of the Bridge Online data dictionary for native requests.
Naming Differences
When the catalog is opened, as with “Exactonlinerest” and schema “Assets” below, a striking difference will surface:
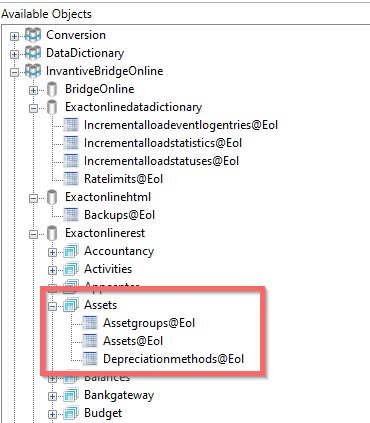
The table name is not Assets but Assets@Eol. This reflects the list of tables displayed in Power BI on Exact Online. The alias of the data container on Invantive Cloud becomes part of the table name from the perspective of the Query Tool. The following statement can be used to query this table:
select *
from Exactonlinerest.Assets.[Assets@Eol]
When an alias bol is defined on the Bridge Online data container, the query would read:
select *
from Exactonlinerest.Assets.[Assets@Eol]@bol
Companies (Partitions)
Another difference also becomes visible from the Query Tool: there is currently no way to choose which Exact Online companies will be used. The list of companies defined in the startup SQL applies; in this case that will be all companies.
When used with Invantive Data Replicator, this considerably decreases granularity. Whereas a direct connection between Data Replicator and Exact Online / SQL Server can individually synchronize each combination of company and table, this is now limited to the table level. Effectively this significantly decreases throughput by using less parallelism but with large environments, there will also be issues in some companies such as overdue invoices leading to a block by Exact Online. Especially for environments with over 1.000 Exact Online companies, the use of Invantive Bridge Online is undesirable, besides that Invantive Bridge Online does not scale well to such volumes for an individual user.
Multiple Data Containers
The data access to Exact Online has been assured. As a next step, define a virtual database for Data Hub and/or Data Replicator in a settings-sample.xml file, such as (refer to format description):
<?xml version="1.0" encoding="utf-8"?>
<settings xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="3" forcedefault="false">
<group name="Sample" id="d7bc8a41-db12-4b75-8664-19a8a52ef5a0" sortingOrder="0" >
<connection name="Sample" id="54d6bdc4-dc09-5ed9-9763-680d05a6b1ba" >
<database
order="10"
alias="bol"
provider="InvantiveBridgeOnline"
userLogonCodeMode="Hidden"
passwordMode="Hidden"
defaultUserLogonCode="john.doe@acme.com"
defaultPassword="secret"
AllowConnectionStringRewrite="false"
connectionString="server=https://bridge-online.cloud;database=acme-exact-online"
/>
<database
order="30"
alias="sqlserver"
provider="SqlServer"
userLogonCodeMode="Hidden"
passwordMode="Hidden"
connectionString="Data Source=sqlserver01.local;UID=myuser;PWD=mypassword"
AllowConnectionStringRewrite="false"
/>
</connection>
</group>
</settings>
The connection will be available to Query Tool, Data Hub, and Data Replicator after scanning the files using the blue “Edit” button:
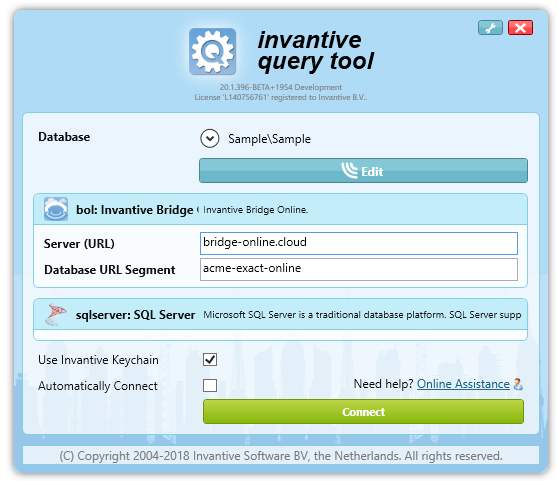
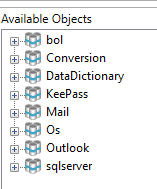
After logging on to the database, a connection is available to multiple data containers:
- One data container
bolfor Exact Online through the Bridge Online server on Invantive Cloud - One data container
sqlserverfor the on-premise SQL Server instance.
The Exact Online data can be retrieved and stored in the current Microsoft SQL Server database using statements such as:
create or replace table journals@sqlserver
as
select *
from Exactonlinerest.Financial.[Journals@Eol]@bol
By repeating these steps for multiple tables, you can easily create a data warehouse or provide a BI tool of your choice with data.
Use Invantive SQL statements to copy, replicate or synchronize the data
Limitations
The replacement of a direct connection with Exact Online by a connection through Invantive Cloud has several limitations/drawbacks. The following limitations of this approach apply, partly already discussed above:
- No partition selection: there is no way to select which companies to process. The decreased granularity requires more effort to run stable for volumes of over 50 companies.
- Reduced speed: the data is processed using less parallelism, which especially decreases performance with over 50 companies.
- No trickle loading: the use of trickle loading is not possible. Please use the
*Incrementaltables instead. - Little server-side filtering: for queries with joins, the Invantive SQL optimizations often do not apply. Queries that would automatically be optimized to use join sets will run considerably longer and require more resources.
- Less control on security: the business data flows through cloud servers, managed by Invantive. Many companies apply on-premise technology and direct connections to reduce the number of external managed components.
- Less scalable: while Data Replicator can easily manage a data warehouse exceeding 1 TB of size, the approach proposed scales less well. For a data warehouse using this approach, we recommend restricting yourself to say 50 GB of managed data.
- Less manageable: Invantive Data Replicator provides automatic metadata management, automatically adapting to the data retrieved. It also includes 24/7 availability through discrete versions. Despite that this approach automatically changes data types, it does not provide 24/7 availability as the tables are gone during copying.