Is er iets aan de hand of gewijzigd aan de backend kant?
Het refreshen van mijn gebruikelijke BI rapport duurt uren.
In Power BI Service lukt het dan ook niet (maar dat is al een paar weken), maar ook in Power BI Desktop is hij intussen al 4 (!) uur bezig om een paar tabellen op te halen.
Queries zijn geoptimaliseerd en ik heb er voor de zekerheid ook maar een filter in gebouwd, zodat alleen de data van het afgelopen jaar opgehaald wordt.
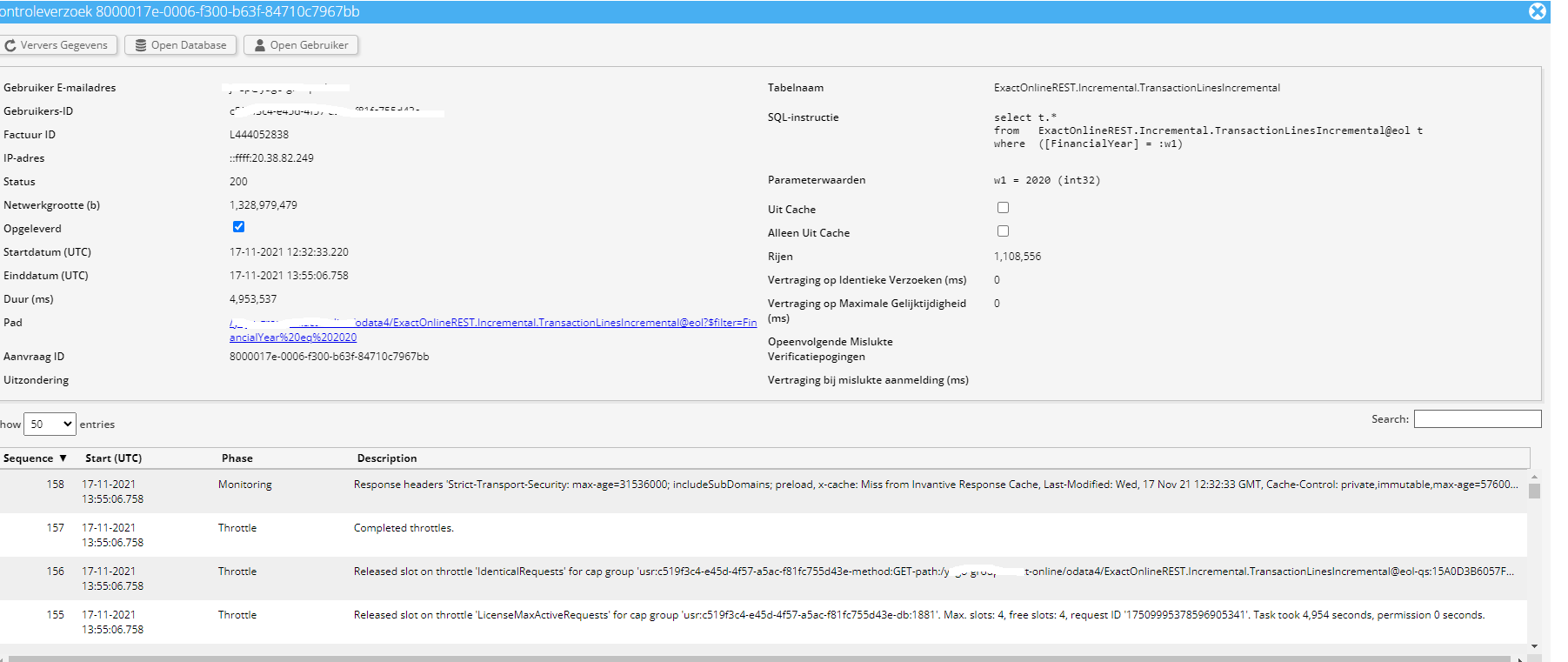
ik ervaar hetzelfde, tabel TransacctionLines met een filter op FinancialYear. Het ophalen van 1 jaar (ongeveer 1 miljoen regels). Duurt nu al langer dan een uur.
Vanochtend lukte dat in een half uur. Gisteren ging dat nog veel sneller. Ik heb het dan over het klaar zetten van de cache, als dat gelukt is gaat het laden in Azure Data Factory en Power BI weer prima. Dus ik start nu de ETL (het laden van 1 FinancialYear). Dat stop ik dan omdat deze anders toch een timeout geeft. Ik wacht tot het klaart staat bij invantive en start dan de ETL opnieuw zodat het laden direct start.
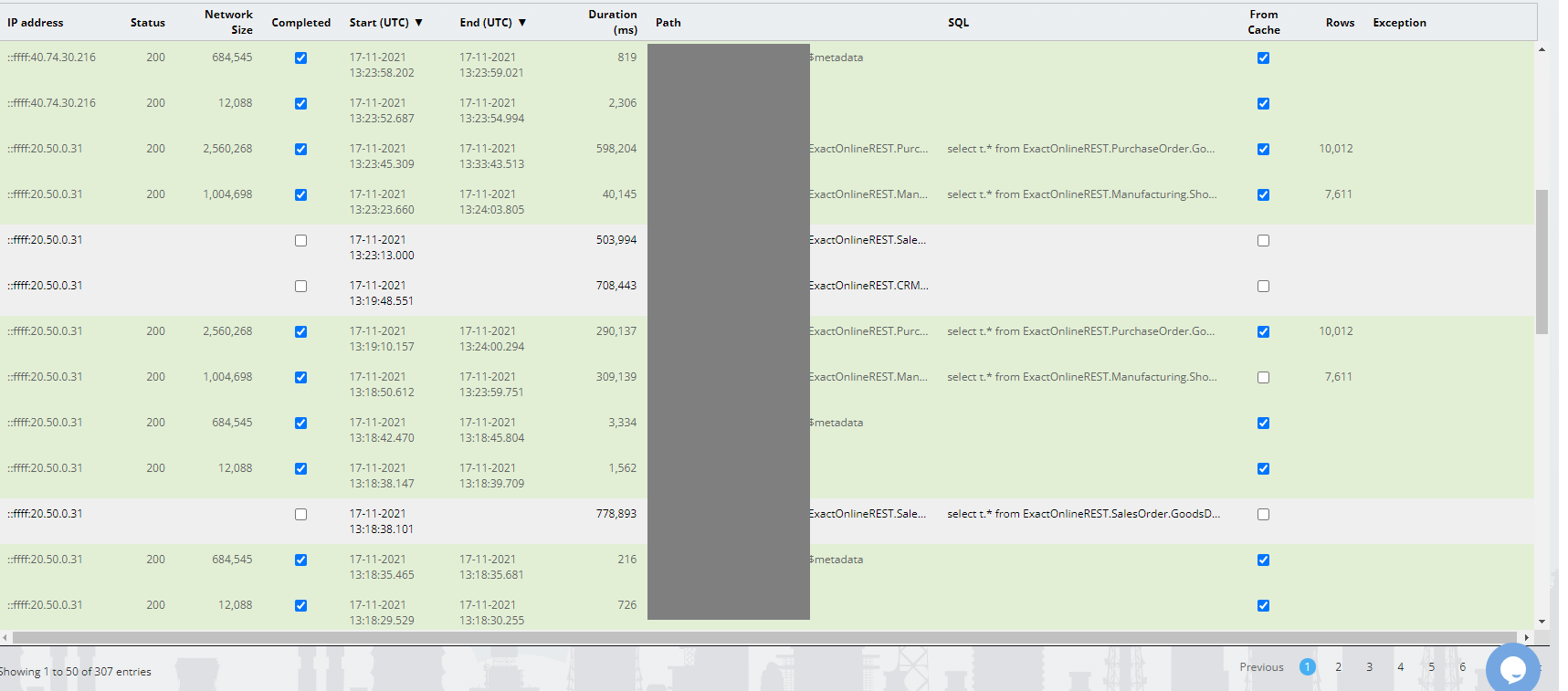
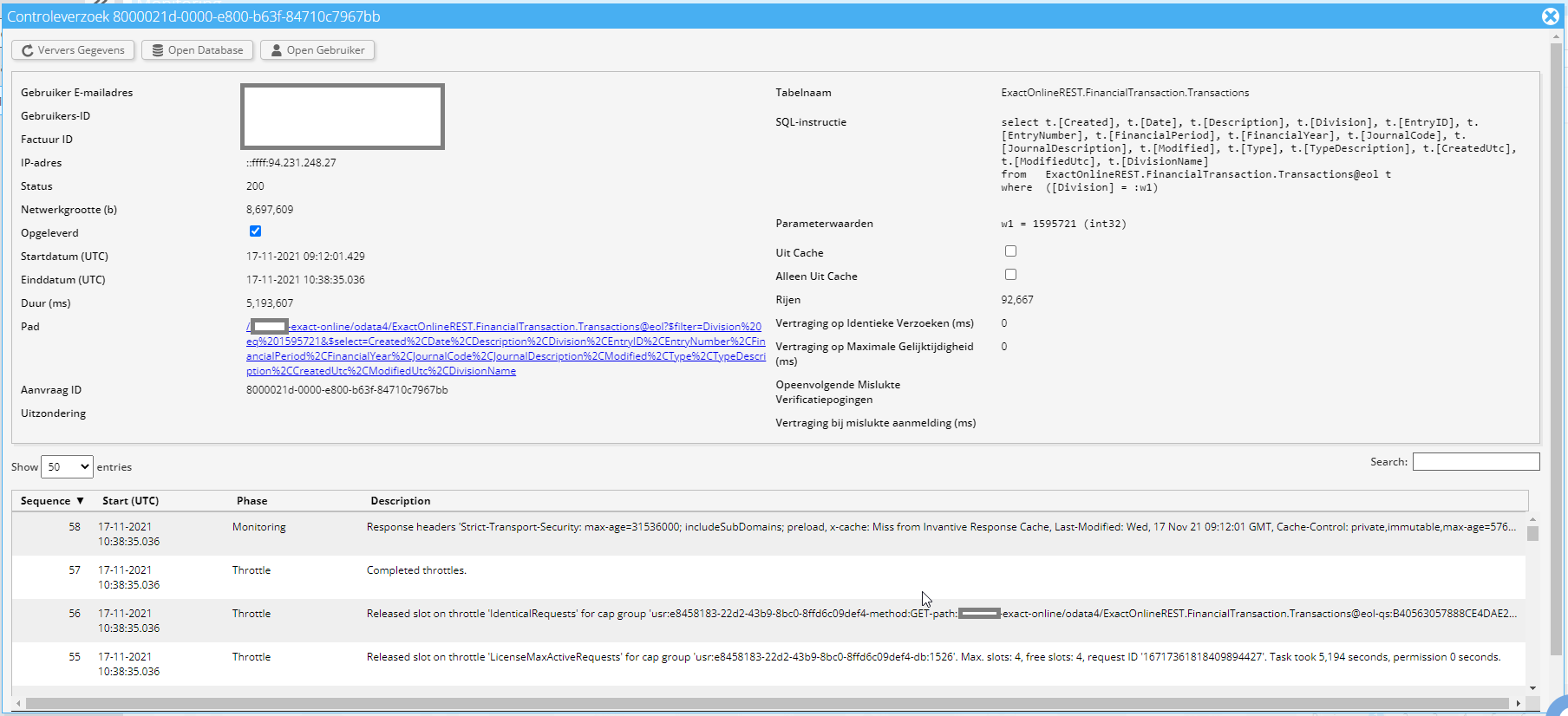
In dit geval gaat het om de tabel ExactOnlineREST.FinancialTransaction.Transactions@eol. Deze is erg langzaam voor de genoemde informatie. Advies is om TransactionLinesIncremental te gebruiken. Die duurt voor de getoonde 92 duizend rijen vele malen tot wel duizend maal korter.
Hou er rekening mee dat de Exact Online API’s momenteel soms erg langzaam kunnen zijn. Het is niet ongebruikelijk dat een enkele API-call tot wel een minuut duurt.
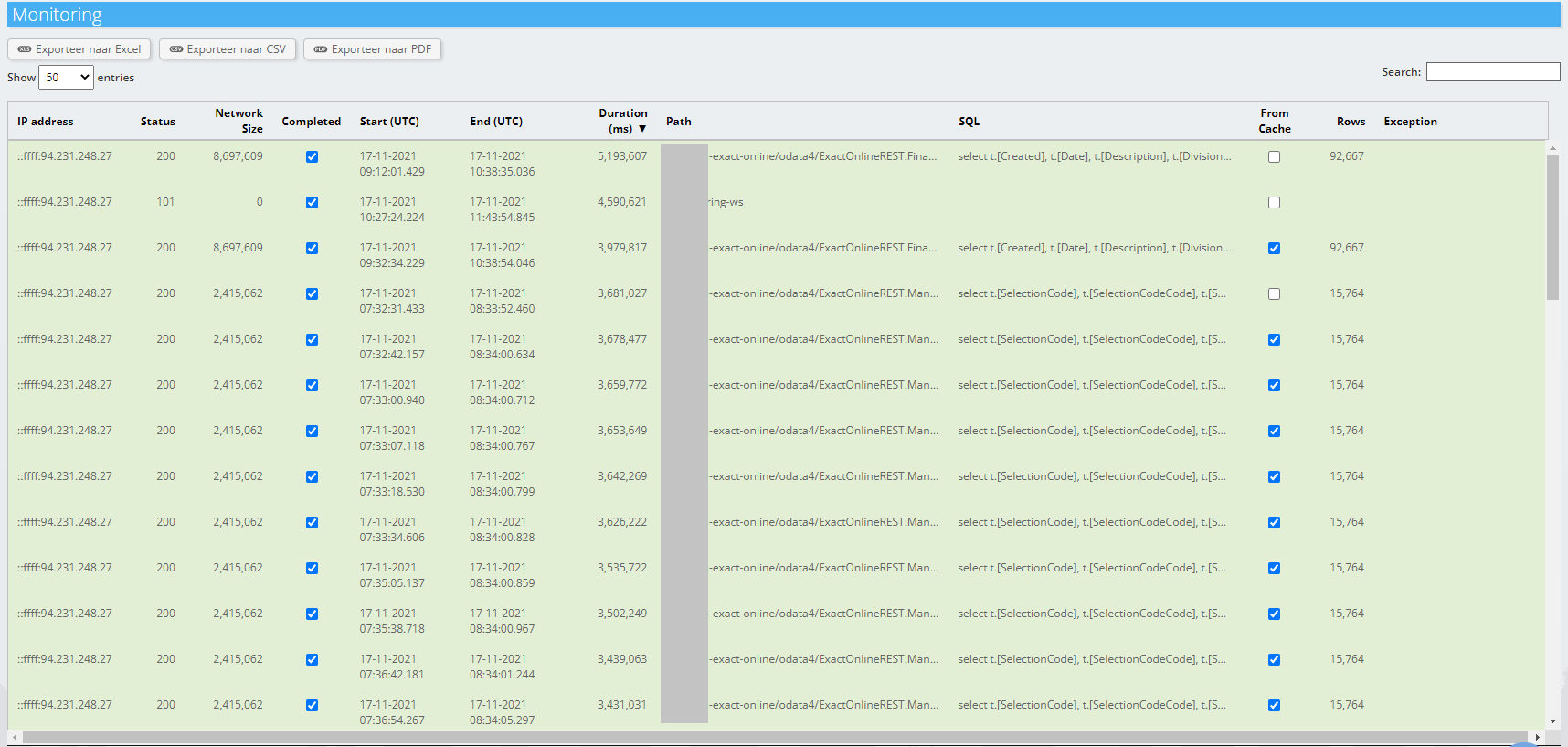
In dit geval was het gemiddeld 3,4 seconden per 60 rijen (5198 / (92667/60)). In 2020 was deze API circa 10x sneller.
Er worden nu écht een paar dingen door elkaar gehaald:
Ik vraag de Transactions-tabel op, niet de TransactionLines-tabel.
Helaas is er geen Incremental-versie van de Transactions-tabel (anders had ik die wel gebruikt), dus
ik ben genoodzaakt om de Transactions-tabel op te vragen.
FYI: Ik gebruik ook de TransactionLines-tabel en daar gebruik ik netjes de incremental-versie van.
Wilfred haalt wél de TransactionLines-tabel op, en hij ervaart ook traagheid.
Een aantal dagen geleden kon ik hetzelfde rapport (niets aan gewijzigd) in ongeveer 1,5 uur
refreshen. Intussen duurt het meer dan 4 uur om dat rapport te refreshen. Dat kan niet komen door
het niet gebruiken van de ‘incremental’-tabel…
Ik ben “as we speak” in Power BI verbinding proberen te maken met de ExactOnline tabellen; hij is
nu intussen al 14 minuten bezig om alleen nog maar de tabellen te laten zien, zodat ik ze kan
selecteren. Vervolgens moet ik ze nog gaan laden, eerst in Power Query en daarna in het rapport…
Ook de tabel Transactions is erg langzaam. Om die reden heeft Exact Online hem enkele jaren geleden de status “Obsolete” gegeven. De aangeraden alternatieve ophaalmethode is TransactionLinesIncremental. De rijen met LineNumber 0 bevatten de transactiekop. Bijzondere regelnummers zijn terug te vinden in Bijzondere regelnummers zoals 9999 op financiële transacties in Exact Online.
Tabel TransactionLines snelheid
De verwerking van de andere gebruiker betreft circa 4 miljoen rijen uit TransactionLinesIncremental, waarvan er na filtering 1 miljoen overblijven. Onderwater wordt hierbij circa het 40-voudige verwerkt in dezelfde tijd, waarbij de memory footprint op Invantive ook circa 40-maal groter is door de algoritmes achter de Sync API’s van Exact Online. Daarom toch het advies om TransactionLinesIncremental te gebruiken voor een hogere snelheid.
Het laden van de lijst van tabellen kan erg lang duren; bijvoorbeeld doordat er voorgaande queries afgebroken zijn maar wel een slot bezet houden. Afhankelijk van het abonnement zijn er meestal tussen de 1 en 8 slots beschikbaar.
Advies is om eerst TransactionLinesIncremental te gaan gebruiken.
Eerst zeg je dat TransactionLinesIncremental een bij 4 miljoen rijen met selectie van 1 miljoen een forse impact heeft op de Invantive servers. En vervolgens adviseer je toch om TransactionLinesIncremental te blijven gebruiken?
De performance kan inderdaad fluctueren, zeker op grote tabellen zoals TransactionLinesIncremental met miljoenen boekingen die geactualiseerd worden. Bij het actualiseren worden tijdelijk alle boekingen in het geheugen geplaatst. Dit kost circa 1.000 - 2.000 byte per regel. Daarna worden de mutaties verwerkt: toevoegingen, mutaties en verwijderde gegevens. Het eindresultaat wordt daarna versleuteld en opgeborgen. Daarna begint de overdracht.
Dit gebeurt op een systeem met meerdere gelijktijdig actieve gebruikers waarbij allen concurreren om de systeembronnen. Helaas is Invantive Cloud nog niet voldoende geoptimaliseerd om zwaar gebruik van resources voldoende af te remmen zodat andere gebruikers relatief veel last hebben van enkele zware gebruikers. Dit gaat niet alleen om CPU-gebruik, maar ook bijvoorbeeld geheugengebruik. Enkele XML-tabellen zijn erg geheugenintensief en vooral accountancygebruikers hebben vaak veel data.
We streven er naar de voorspelbaarheid van de looptijd van queries te verbeteren door relatief zware queries af te remmen, rekening houdend met de abonnementsvorm.
Is het niet zo dat juist door het gebruik van de Sync API (bij Invantive de Incremental tabellen) de opvraag van data naar Exact minimaal is (ik vermoed dat jullie met de Timestamp werken?), maar daardoor omdat je op ID (key) moet vergelijken de load bij Invantive juist heel zwaar is?
Zou dat niet pleiten om dan toch de BULK api te gebruiken, als ik een filter op FinancialYear gebruik?
Alhoewel je dan bij 1 miljoen regels al 1000 (van de straks 5000 limit) gebruikt heb bedenk ik me nu…ergens zit de pijn.
M.b.t. prestaties: de prestaties van de Exact Online API’s zijn de afgelopen tijden ronduit beroerd. Het valt niet mooier te maken; de responsetijden variëren met een factor 100 ten opzichte van een jaar eerder en de onderste 10-percentiel zijn serieus omhooggeschoven. Aangezien Invantive Cloud near real-time werkt, voelen gebruikers dit meteen. Advies is om 's nachts de data op te halen. Als dat een keer 10x langer duurt, dan is dat minder merkbaar.
M.b.t. ophalen tabellenlijst: als er bijvoorbeeld 4 slots beschikbaar zijn, en het ophalen is erg veel langzamer dan blijven meer slots langdurig bezet. Ook het ophalen van de tabellen moet soms door 1 van de vier poortjes.
Ik verwacht dat met overgang van Transactions naar TransactionLinesIncremental de ervaren problemen vele malen kleiner worden.
Dat is correct geformuleerd; Invantive Cloud dient als off-loader van de Exact Online API’s. De hoeveelheid rekenkracht benodigd voor de *Incremental tabellen en vooral voor grote omgevingen is serieus veel hoger dan voor *Bulk. Ook de filtermogelijkheden zijn enorm uitgekleed, waardoor er vaak onnodig veel API-calls nodig zijn. Het grote plaatje ontgaat me bij tijd en wijle; het lijkt er op dat de goeden lijden onder de hardleerse.
Anyway, het is zoals het is. Exact zal het API-gebruik uit kostenoverwegingen voorlopig steeds verder beperken en dat is begrijpelijk voor administraties die een paar Euro per maand kosten, maar toch soms miljoenen boekingen bevatten. Er wordt op dit moment nog niet gedifferentieerd tussen een administratie van zeg 3 Euro en een van zeg 3.000 Euro per maand qua toegestaan API-gebruik. Volgens het organisatiegroeidiagram zal deze differentiatie op enig moment komen.
Het teruggaan naar *Bulk raden we af; Exact zal intensief gebruik verder afremmen.
Vanuit Invantive zullen we optimalisaties maken in de gegevensstromen en we proberen ook Microsoft zover te krijgen om dit met Power BI te doen, dus Likes welkom:
Advies is om zoveel mogelijk TransactionLinesIncremental te gebruiken. Exact is vastbesloten om het gebruik van TransactionLines, GLTransactionLines en TransactionLinesBulk terug te dringen.
Een deel van de verschuiving van de load zal Invantive Cloud kunnen verwerken, een ander deel zal mogelijk ook invloed hebben op de eindgebruikerservaring.
Misschien nog goed om te vermelden dat de belasting voor een groot stuk ook veroorzaakt wordt door het grote datavolume en de strikte eisen die we stellen aan de beveiliging. De meeste alternatieve oplossingen zetten minder zwaar of niet in op het versleutelen van vertrouwelijke gegevens. Het ontsleutelen en versleutelen van gigabytes aan informatie kost gewoon veel prestaties, en het is nog niet goed mogelijk om met subpartities te werken hiervoor om de rekentijd te beperken.
De release van komende maandag zal in een aantal scenario’s op de *Incremental-tabellen een aantal geheugenoptimalisaties bevatten. Hierdoor zal in een aantal edge cases het geheugengebruik sterk afnemen bij grote datasets (4-10 miljoen rijen). Dergelijke volumes in 1x downloaden via *Incremental lopen momenteel tegen de fysieke grens van het beschikbare werkgeheugen van de gebruikte servers aan. De piekbelasting wordt circa 10% lager, maar de piekbelasting komt minder vaak voor door soms een andere strategie te kiezen voor het samenvoegen van wijzigingen in de voorgaande complete versie.
Voor de langere termijn kijken we naar de mogelijkheid om datasets tot 20 miljoen rijen te verwerken door meerdere batches en overstap naar een ander clusterarchitectuur. Als dat lukt, zal het nieuwe cluster ook meer mogelijkheden geven om nieuwe versies geleidelijk uit te rollen en door te groeien naar een circa 10-voudige capaciteit. Het aantal gebruikers is dusdanig sterk gegroeid dat 24x7 geen momenten meer zijn dat niemand actief is.