In dit topic leer je hoe je geautomatiseerd in 1x alle documenten (PDF, Word documenten, etc.), webpagina’s en afbeeldingen van een website kunt downloaden met Invantive SQL. Deze benadering werkt zowel voor een specifieke website, maar ook voor meerdere websites of - als je heel wild doet - elke website op het hele Internet.
De heel korte versie is het volgende SQL statement:
select *
from internettable
( 'https://rdw.nl/over-rdw'
stay on site
ignore errors
)
where retrieval_successful = true
met als resultaat:
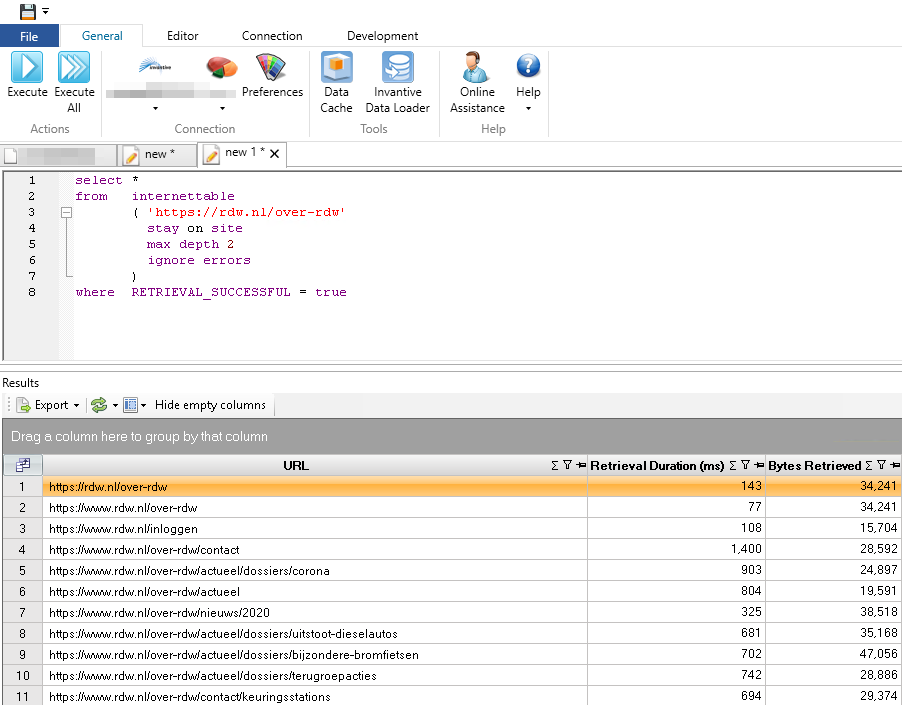
Voorbereiding voor Sites Downloaden
Vooraf dien je een aantal voorbereidingen te treffen:
- Installeer Invantive Query Tool op Microsoft Windows.
- Start Invantive Query Tool.
- Kies de (gratis) Open Data licentie.
- Wacht tot de ontdekkingstocht klaar is.
- Kies in de lijst van databases de “Dummy” database.
- Klik op “Aanmelden”.
Je bent nu klaar om de inhoud van sites te downloaden.
Download een Site
De eenvoudigste download is het ophalen van een enkele website door te “crawlen” zoals ook Google dat doet. HTML-pagina’s zijn dan de enigen die weer verwijzen naar andere HTML-pagina’s, plaatjes, bestanden of downloads. Het downloaden begint bij bijvoorbeeld de URL van de hoofdpagina.
Plak het volgende statement in de editor:
select *
from internettable
( 'https://rdw.nl/over-rdw'
stay on site
max depth 2
ignore errors
)
where retrieval_successful = true
In dit geval wordt de inhoud van de website van het RDW op het Internet opgehaald tot maximaal 2 stappen vanaf de beginpagina. De betekenis van dit SQL select-statement kun je ook terugvinden in de Invantive SQL grammatica.
Als je het statement wilt opslaan, kies dan het Bestandsmenu en “Opslaan”.
Voer vervolgens het statement uit door linksboven op de knop “Uitvoeren” te drukken (of gebruik ctrl+Enter. Met “Uitvoeren” wordt het statement onder de cursor uitgevoerd. Als er meerdere SQL of script-statements staan, dan kun je ze allemaal met “Alles Uitvoeren” draaien. Elk statement dat door een of meer witregels gescheiden is van een ander statement wordt dan achtereenvolgens uitgevoerd.
Invantive SQL zal met een aantal “crawlers” tegelijk de informatie van de site downloaden en intern opslaan. Ook worden verwijzingen over het Internet gevolgd om echt alle bestanden te kunnen vinden. Vooral de a-HTML tag zal hiervoor gebruikt worden. Echter, omdat we “stay on site” opgeven zullen de crawlers niet verder gaan buiten de opgegeven site, los van eventuele wisselingen tussen de www.naam.nl en naam.nl naam.
Gedurende het crawlen wordt de oorspronkelijke lijst van pagina’s telkens uitgebreid met verwijzingen naar pagina’s die vallen binnen de criteria (in dit geval: van dezelfde website), terwijl onderwijl andere crawlers de lijst verder afwerken. Uiteindelijk zul je hierdoor alle pagina’s van een website vinden die interne links hebben vanaf de startpagina.
De crawlers van Invantive SQL houden geen rekening met robots.txt instellingen. Een robots.txt bestand is niet meer dan een hint, maar voor bijvoorbeeld onderzoeksdoeleinden is een robots.txt-bestand onwenselijk.
Crawlen met een XML-sitemap
Veel sites hebben ook een zogenaamde “sitemap”. Dit is een XML-bestand dat meestal staat op IDNL. De sitemap heeft een standaarindeling volgens een Internet-standaard. Een sitemap helpt crawlers om snel alle unieke URL’s te achterhalen en wanneer ze voor het laatst gewijzigd zijn. Met Invantive SQL kun je ook een of meer sitemaps opgeven. In onderstaand voorbeeld wordt niet alle de hoofdpagina gebruikt als startpunt, maar ook de inhoud van twee sitemaps:
Merk op dat we hier gebruik maken van een zogenaamde “array” om bij een parameter meerdere sitemap download URL’s te kunnen opgeven en we de uitvoer afkappen na 500 downloads.
select *
from internettable
( 'https://rdw.nl/over-rdw'
sitemap array['https://rdw.nl/sitemap.xml', 'https://rdw.nl/sitemap-die-niet-bestaat.xml']
stay on site
max depth 2
ignore errors
)
limit 500
Crawl Meerdere Websites
Je kunt ook meerdere websites in 1x downloaden. Dat is vooral handig en efficient als het websites die met elkaar samenhangen, bijvoorbeeld omdat de pagina’s intensief onderling verweven zijn met links: een pagina op bijvoorbeeld forums.invantive.com verwijst naar documentation.invantive.com of vice versa. Voor het downloaden van alle webpagina’s van meerdere sites gebruik je een array zoals eerder ook bij de sitemaps:
select *
from internettable
( array['https://rdw.nl/over-rdw', 'https://invantive.nl']
stay on site
ignore errors
)
Van een array met constanten moet vooraf bekend zijn hoeveel elementen hij heeft. Gebruik de SQL-functie to_array aIs de lijst variabel is, zoals bijvoorbeeld met het functioneel identieke:
select *
from internettable
( to_array('https://rdw.nl/over-rdw$$$https://invantive.nl', '$$$')
stay on site
ignore errors
)
Filteren op Soort Bestand
Je kunt de Internet-downloads beperken tot een deel van de bestanden, bijvoorbeeld alleen de afbeeldingen, HTML webpagina’s of PDF-bestanden. Gebruik hiervoor een “where” clause op bestandsnaam, URL of MIME-type:
select *
from internettable
( array['https://rdw.nl/over-rdw', 'https://invantive.nl']
stay on site
ignore errors
)
where mime_type = 'application/pdf'
Downloads/Bestanden Opslaan
Na het ophalen van de downloads wil je ze ook waarschijnlijk opslaan op je eigen computer. Je kunt ze natuurlijk ook meteen verder verwerken met bijvoorbeeld HTMLTABLE en zo verdere analyseren. Het opslaan op de eigen computer in een map gaat met het volgende statement:
select contents_blob
, regexp_replace(urldecode(returned_url), '.*/', '') my_file_name
from internettable
( 'https://www.roermond.nl/'
stay on site
max depth 4
ignore errors
)
where mime_type = 'application/pdf'
limit 5
local export documents in contents_blob to "c:\temp" filename column my_file_name
Afhankelijk van de hoeveelheid bestanden die je gedownload hebt van het Internet duurt dit enkele seconden of minuten tot alle downloads in de opgegeven map staan.
Je kunt ook een klik met de rechtermuisknop gebruiken en kies dan “Save selected cell contents as file”. De klik met de rechtermuisknop is handig als je eenmalig een paar bestanden wilt downloaden en opslaan. Met het “local” statement kun je een script maken dat elke dag opnieuw draait, elk document van het Internet plukt en elk download opslaat.