Summary
This note presents a number of easy steps to improve the compliance to GDPR (“General Data Protection Regulation”) of your data warehouse.
Non-technical recommendations are given as typical low-hanging fruit. GDPR pseudonymization is correlated to the Swiss banking system (more on it in ‘Asterix in Switzerland’).
A number of technical examples are included. These use Invantive SQL as typically used in combination with Exact Online, SQL Server/PostgreSQL and Invantive Data Replicator.
Advantages of Fraud for GDPR
The General Data Protection Regulation is in my humble opinion only a confirmation of good practices already established in the past and partially enforced. Many organizations have a carefully managed registration of sensitive data in their operational systems, such as accounting, sales, or service. This especially holds for organizations with multiple job titles working together in one system; the risk of fraud prevents careless allowing everyone to change the bank number of a supplier.
The risk of fraud is one of the best reasons for company owners to make sure sensitive data is well protected:
- it has a direct impact on the bottom line,
- it is easy to understand,
However, fraud prevention is not always tightly bound to data security and confidentiality for personal data. For instance, a data warehouse, in general, does send payment orders to your bank but still contains confidential sensitive personal information.
“Gimme the Data” and Data Warehouses
In real life, you will find many small and large organizations that run a data warehouse to which many people have access without any form of differentiated authorization. Once you are in (so you have authenticated yourself), you have access to the personal data of thousands, sometimes even including very personal data.
Often, this is combined with the lack of an audit trail for interactions (“you could have seen the information”). Even when data leaks, the lack of an audit trail ensures that it is very hard to establish what has been leaked. However, there is no direct impact on the bottom line of the company of a leak. A highly valued customer once explained to me that there is no financial valuation for compliance in such cases; comply or wait for the accident to happen and hope your company is still viable afterward.
Comply or wait for the accident to happen and hope your company is still viable afterward.
Low-hanging Fruit
There are very cheap ways to quickly mitigate the risks of a data warehouse:
- Set up an audit trail, such as on database or application level. This ensures you might be able to discover what data was leaked afterward.
- Make sure the audit trail is tamperproof. This ensures that the malicious person can not remove his trails.
- Reduce the number of people that can access the data warehouse. This reduces the chance of a leak.
- Assess the integrity of the remaining persons. This reduces the chance of a leak.
- Promote responsible disclosure internally and externally of risks. This ensures known fraud options do not exist forever, even when it hurts to get bad press.
- Make sure it hurts to leak within the extents of the law. This reduces the chance of a leak.
There are more complex ways to further reduce the risks of having a data warehouse, such as:
- Apply authorization and partition data vertically and/or horizontally. This ensures that the data is only accessible on a need-to-know basis.
- Avoid the presence of confidential personal data. This ensures there is nothing to leak.
The application of authorization on data partitioning on a data warehouse can be quite hard to achieve afterward, since most data warehouses were not designed with authorization in mind. It is nonetheless possible; at Invantive we’ve shipped such warehouses for almost twenty years using a combination of generation of a data warehouse with automatic ETL.
Personal Data
The avoidance of the presence of confidential personal data in a data warehouse can be achieved in two ways:
- Do not load personal data into your data warehouse.
- Anonymize personal data in your data warehouse.
There is little to tell about the first one: just don’t load the data and your problem is solved!
But that can be hard to reach.
Often the sensitive data loaded from various sources must be matched on personal data such as actual name, address, date of birth, social security number, email address, and so on. In fact, for GDPR personal data is information from which you can derive the actual person. As a data warehouse builder, you of course prefer anything that uniquely identifies a person. Even the slightest piece of non-uniqueness makes the loading process harder. But article 4 of GDPR defines not only unique personal data as personal data but even something from which someone indirectly might be able to determine the actual person, such as the “blond guy living in that white house at the left side of the street”.
‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person;
Source: Article 4 GDPR Definitions
And even after the loading process finished, the raison d’être of your data warehouse might be the ability to uniquely report on individuals…
So when your output absolutely requires the inclusion of personal data, you will have to make sure that your data warehouse is protected as well as your operational systems, including authorization and an audit trail. But anonymization (or as GDPR calls it ‘pseudonymization’) often provides an alternative. Thanks to the Swiss.
Pseudonymization, made in Switzerland
Technology can be used for the good or for the bad. The Swiss have an excellent banking system that supports numbered bank accounts. From the title of a bank account you can not determine the beneficiary of the account. And yes, numbered bank accounts, especially when combined with a password and full anonymity, are a great way to hide money gained from illegal business and other malpractices to make sure crime pays.
But this technology of assigning a random number to a bank account can also be used for the good. It seems that the Swiss banks can run great management reports using numbers to identify accounts. Do the numbered bank accounts implement GDPR compliance? Yes, it is close to impossible to determine the actual person without a court order. GDPR covers this as follows:
‘pseudonymisation’ means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person;
Source: Article 4 GDPR Definitions
As said before, GDPR requires nothing new; the Swiss did it already in the Roman time as can be found in the ultimate reference on history ‘Asterix in Switzerland’.
Subsequent articles further elaborate that ‘pseudonymization’ (or ‘anonymization’ as I like to call it) reduces the risks for leaking personal data.
Implementing Pseudonymization
In your data warehouse, you can apply pseudonymization to uniquely identify persons, as long as you protect access to the translation tables used for pseudonymization. There are several variants for pseudonymization:
- map multiple persons into one pseudonym (a surjective mapping).
- map each person into one pseudonym and vice versa (a bijective mapping).
Although a mapping that is solely surjective might be applicable in some very sensitive areas to achieve data protection, it is very hard to handle. In general, a bijective mapping is easier to understand and implement organizationally since a number refers to a unique person and a unique person refers to the same specific number.
Note that such a bijective mapping is the same as data encryption and data decryption.
Over the years, we’ve implemented pseudonymization in various real-time data warehouses. This technology is only available for large enterprises. However, we have added similar functionality to the SQL engine used for the low-priced Invantive Data Replicator, which automatically loads operational data stores and data vaults from operational systems.
Local security policy and information processing needs dictate whether production data should be pseudonymized or not. The same holds for a test environment: depending on the organisational measures applied such as to avoid unauthorized access, pseudonymization might be required or optional.
Invantive SQL Anonymize Statement
I will use the Invantive SQL statement anonymize to show how pseudonymization can be implemented.
The anonymize statement anonymizes a text or number. Anonymization is executed such that when the same original value is anonymized within the same session, the anonymized value will be identical. The anonymized value also uniquely matches the original value. With no access to the anonymization map however, the original value can however not be calculated from the anonymized value.
In mathematics, the anonymization function is a bijection as stated above: each element of the original set is paired with exactly one element of the anonymized set, and each element of the anonymized set is paired with exactly one element of the original set.
The anonymize function has two or three parameters:
- Value: A text or number to be obfuscated.
- Maximum length (optional): Maximum length in digits for numbers or characters for text of anonymized value. Null means no restriction on the maximum length.
- Mapping (optional): algorithm to use. The default algorithm is ‘DEFAULT’ which maps text values to a range of hexadecimal characters and numbers to a range of numbers. Alternative mappings are described below.
The following anonymization maps are available on installation:
- DEFAULT: the default algorithm.
- IVE-GL-JOURNAL-DESCRIPTION: general ledger journal descriptions: no preferred anonymizations, leave familiar and non-confidential descriptions in original state.
- IVE-GL-ACCOUNT-DESCRIPTION: general ledger account descriptions: no preferred anonymizations, leave familiar and non-confidential descriptions in original state.
- IVE-PSN-FIRST-NAME: person first names: prefer readable alternative first names, anonymize all.
- IVE-PSN-LAST-NAME: person last names: prefer readable alternative last names, anonymize all.
- IVE-ADS-CITY-NAME: address city names: prefer readable alternative city names, anonymize all.
- IVE-ADS-STREET-NAME: address street names: prefer readable alternative street names, anonymize all.
The data dictionary contains the anonymization maps used so far in the session and their corresponding values:
- Anonymization mappings in use: SystemAnonymizationMaps@DataDictionary
- Mapped values: SystemAnonymizationMapValues@DataDictionary
- Pre-defined mapping: SystemAnonymizationPredefinedMaps@DataDictionary
Pseudonymizing Names
First let’s prepare some personal data. There is no table available so a query on a XML document will be used:
create or replace table persons@inmemorystorage
as
select xml.first_name
from xmltable
( '/persons/person'
passing '<persons><person><first>Guido</first></person><person><first>Maria</first></person><person><first>Peter</first></person></persons>'
columns first_name varchar2 path 'first'
)
xml
Result is:
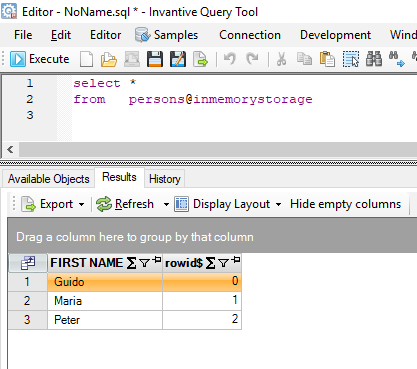
Next, we will use the anonymize SQL function to generate some “numbered” persons:
select first_name
, anonymize(first_name)
from persons@inmemorystorage
Result is:
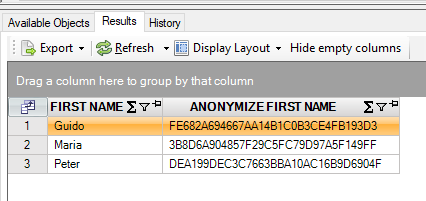
The name ‘Peter’ is mapped to ‘DEA199DEC3C7663BBA10AC16B9D6904F’. This mapping is consistent: whenever you anonymize the first name ‘Peter’ again, the outcome will always be identical:
select anonymize(first_name)
from persons@inmemorystorage
join range(10)@datadictionary
where first_name = 'Peter'
Result is:
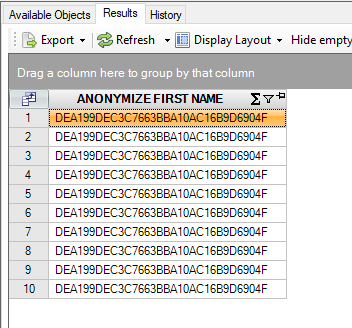
This number now uniquely identifies Peter. But, during for instance presentations to the public or a customer you would like to just replace ‘Peter’ with another first name to make sure the output still seems realistic, but still not present actual personal data. This can be achieved by using one of the pre-defined maps, in this case for first names:
select first_name
, anonymize(first_name, null, 'IVE-PSN-FIRST-NAME')
from persons@inmemorystorage
Result is:
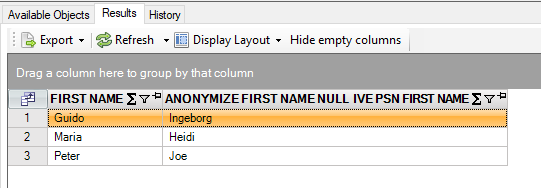
Despite a gender change here and there, the results seem realistic.
At the end of the process, you definitely want to save the pseudonymization mapping for future reference. Store it with great care; when the mapping is lost it will be at best very hard to derive the personal data from the pseudonymized variants. As GDPR requires, the mapping should be kept separately from the data.
The mapping of sensitive information to pseudonymized data is similar to an encryption key used for symmetric encryption.
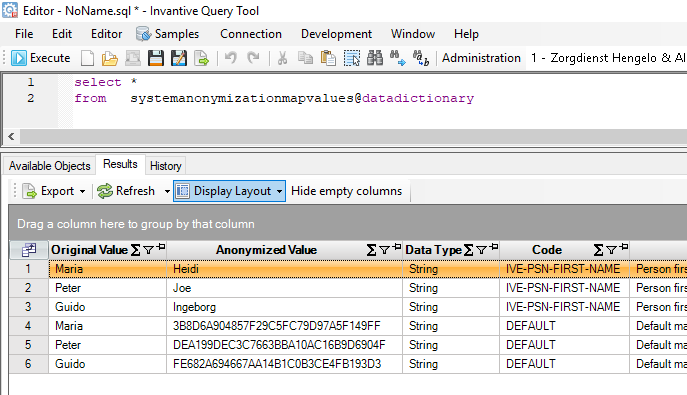
Use the following query to get your pseudonymization mapping:
select *
from systemanonymizationmapvalues@datadictionary
Results with pseudonymized data: