Summary
A global innovation on top of Invantive SQL enables one-statement synchronization (mono- as well as bi-directional) of reference data between applications. This note is the first of a series and explains the advantages, the concept and the grammar.
Data Synchronization for Reduced Costs and Happy Customers
With the advent of apps, your business data has gotten distributed across multiple apps instead of all in one big ERP-system. Apps make your business agile and reduce your costs. Some of your data is stored only once in a specific app, but reference data such as projects, accounts and articles are typically stored and maintained in multiple apps. With business acquisitions, your business even gets more data sets which need to be synchronized for an optimal flow of your business processes and happy customers.
Invantive introduces a global innovation on top of Invantive SQL, which extremely simplifies the synchronization and maintenance of reference data across over 50 platforms, including Salesforce, Visma, Exact Online and Teamleader. This innovation also enables synchronization and maintenance of reference data across partitions of partitioned platforms, like synchronizing articles across multiple Exact Online companies.
In a series of notes you will learn how based on a number of samples to effectively simplify your business processes for reduced costs and improved customer satisfaction. In this note we will introduce the new Invantive SQL feature for synchronization and analysis of data.
Other notes are:
- Synchronize Exact Online with Visma.net
- Custom logic triggers on data synchronize statement for easier data integration
- Synchronize Customers Across Exact Online Companies
- Kostenplaatsen in Exact Online synchroniseren over meerdere administraties (Dutch)
Simple Bi-directional Synchronization Use Case
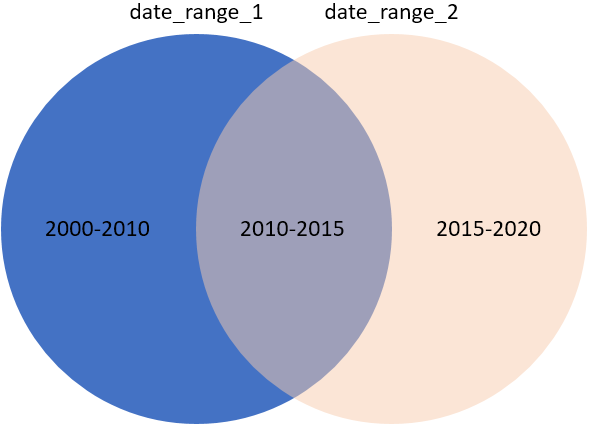
In a simple use case we will bi-directionally synchronize two overlapping data sets, each with some date range.
Original situation:
Synchronization result:
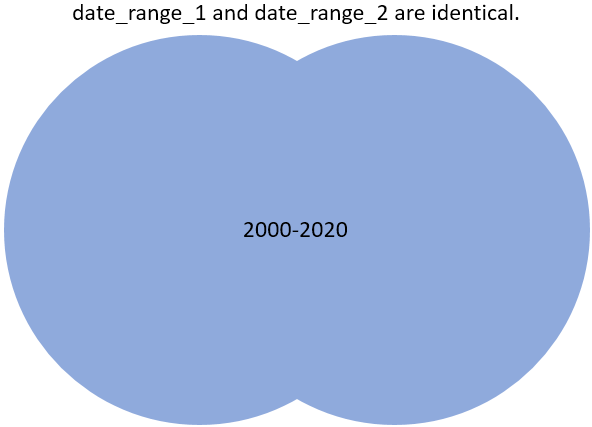
These two data sets will be set up in Invantive’s in-memory data container to work with:
-
date_range_1: selects an arbitrary date range between 1-1-2000 and 1-1-2015 from the data dictionary’s calendar table. -
date_range_2: selects another date range, which partially overlaps date_range_1: all dates between 1-1-2010 and 1-1-2015 occur both in date_range_1 as well as in date_range_2. Additionally, the range 1-1-2015 to 1-1-2020 is included in date_range_2.
The following SQL is used to set up these data sets:
create or replace table date_range_1@inmemorystorage
as
select *
from calendar@datadictionary
where day_date between to_date('01-01-2000', 'DD-MM-YYYY') and to_date('01-01-2015', 'DD-MM-YYYY')
create or replace table date_range_2@inmemorystorage
as
select *
from calendar@datadictionary
where day_date between to_date('01-01-2010', 'DD-MM-YYYY') and to_date('01-01-2020', 'DD-MM-YYYY')
These data sets are different, but a simple SQL statement will bi-directionally synchronize their contents:
- Ensure that all dates occurring in date_range_2, also occur in date_range_1.
- Vice versa: ensure that all dates occurring in date_range_1, also occur in date_range_2.
End result is that both date_range_1 as well as date_range_2 contain all dates from 1-1-2000 to 1-1-2020.
The following SQL is used to synchronize the data sets:
synchronize date_range_1@inmemorystorage
and date_range_2@inmemorystorage
identified
by day_date
resolve prefer left
That is all needed for a high-performance bi-directional synchronization across one or multiple apps!
The matching on rows in date_range_1 and date_range_2 occurs on the contents of the column day_date.
There will be no update conflicts in this case, but would any have occurred, the ‘resolve prefer left’ ensures that contents of date_range_1 would have taken preference and the contents of date_range_2 would have been overwritten.
Synchronize and Compare SQL Statement
In this section I will introduce you to the new statements; future notes will show you samples how to synchronize data across data containers such as Exact Online and Outlook, Visma and Outlook and between Exact Online companies.
These new compare and synchronize statements provide one-directional and bi-directional analysis and alignment of data in two tables. It is an extended version of SQL statements like ‘upsert’ and ‘merge’ found in other SQL implementations, suitable for large volumes and high update frequencies typically found in large enterprises.
The grammar can be depicted as:
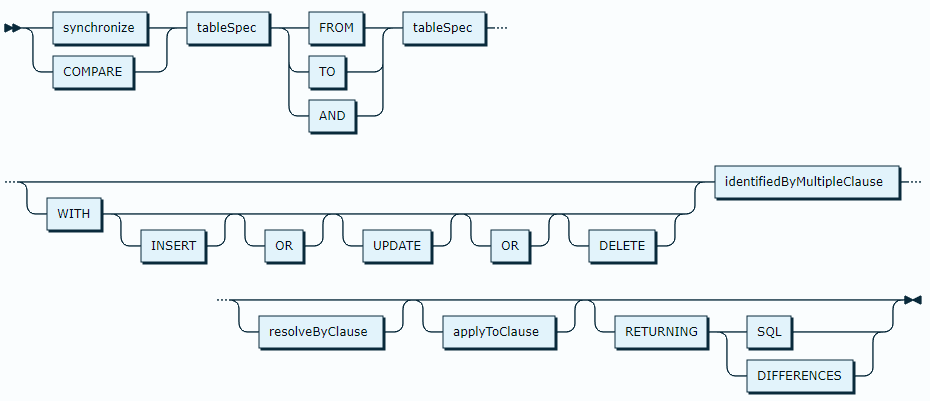
In an one-directional approach as specified by ‘FROM’ or ‘TO’, the compare and synchronize statement typically analyzes the differences between two tables with identically named columns, separating all differences in one out of four groups:
- insert: a row exists in the source table and not in the target table;
- delete: a row exists not in the source table, but exists in the target table;
- update: the row exists in both tables, but the column contents are different.
- none: the row exists in both tables and the column contents are equal.
Rows in both tables are matched using the list of columns as specified by ‘IDENTIFIED BY’. Identifying column null contents are considered a specific value for matching; when both the source and target table have a null value, the rows will be matched.
After analysis, the differences can be filtered to only contain the type of operations specified using ‘WITH’ and then either be:
- applied on the target table to make the tables equal, using bulk operations where supported.
- returned as a list of content differences;
- returned as Invantive SQL DML-statements to achieve synchronization.
After analysis, the differences can be applied on the target table.
In a bi-directional approach, as specified by using the keyword ‘AND’ between the two table identifiers, deletes will not be returned from the analysis phase and replaced by inserts on the table which does not have the other table’s row. The determination of the target for an update is based upon the resolution preference as defined by the ‘RESOLVE’ clause. The ‘RESOLVE’ clause either defines to always apply updates to the left or right table as listed in their order using, respectively, ‘PREFER LEFT’ and ‘PREFER RIGHT’. Otherwise, the combined ordinal value of the columns listed in the ‘RESOLVE BY’ clause will be evaluated and the highest-ranking value is considered to be leading.