Samenvatting
Een unieke innovatie voor Invantive SQL maakt één-statementsynchronisatie (zowel mono- als bi-directioneel) van stamgegevens tussen cloudplatformen mogelijk. Dit artikel is de eerste van een serie en legt de voordelen, het concept en de grammatica uit.
Gegevenssynchronisatie voor lagere kosten en tevreden klanten
Met de komst van apps zijn uw bedrijfsgegevens verdeeld over meerdere apps in plaats van over één groot ERP-systeem. Apps maken uw bedrijf wendbaar en verlagen uw kosten. Sommige gegevens worden slechts eenmaal in een specifieke app opgeslagen, maar stamgegevens zoals projecten, rekeningen en artikelen worden doorgaans in meerdere apps opgeslagen en onderhouden. Met bedrijfsovernames krijgt uw bedrijf zelfs meer datasets die gesynchroniseerd moeten worden voor een optimale uitvoering van uw bedrijfsprocessen en tevreden klanten.
Invantive introduceert een wereldwijde innovatie bovenop Invantive SQL, die de synchronisatie en het onderhoud van stamgegevens over meer dan 50 platformen, waaronder Salesforce, Visma, Exact Online en Teamleader, extreem vereenvoudigt. Deze innovatie maakt ook synchronisatie en onderhoud van referentiegegevens over partities van gepartitioneerde platformen mogelijk, zoals het synchroniseren van artikelen over meerdere Exact Online administraties.
In een reeks artikelen leert u aan de hand van een aantal voorbeelden hoe u uw bedrijfsprocessen effectief kunt vereenvoudigen voor lagere kosten en meer klanttevredenheid. In dit artikel introduceren we de nieuwe Invantive SQL functie voor synchronisatie en analyse van gegevens.
Andere artikelen zijn:
- Exact Online synchroniseren met Visma.net Financials
- Eigen logica in triggers voor datasynchronisatiestatement voor meer gemak
- Kostenplaatsen in Exact Online synchroniseren over meerdere administraties
Eenvoudige use case bidirectionele synchronisatie
In een eenvoudige use case zullen we twee overlappende datasets in twee richtingen synchroniseren, elk met een bepaald datumbereik.
Oorspronkelijke situatie:
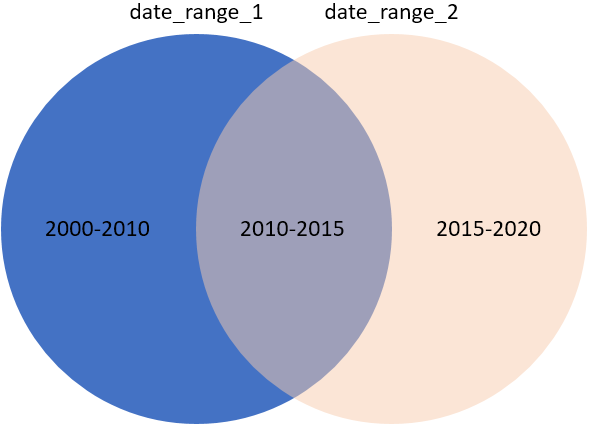
Synchronisatieresultaat:
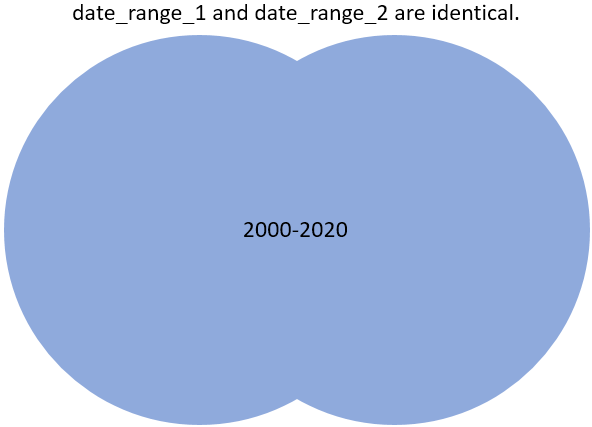
Deze twee datasets worden geladen in Invantive’s in-memory datacontainer:
date_range_1: selecteert een willekeurig datumbereik tussen 1-1-2000 en 1-1-2015 uit de kalendertabel van het datadictionary.date_range_2: selecteert een ander datumbereik, dat date_range_1gedeeltelijk overlapt: alle data tussen 1-1-2010 en 1-1-2015 komen zowel in date_range_1als in date_range_2 voor. Bovendien is het bereik 1-1-2015 tot 1-1-2020 opgenomen in date_range_2.
De volgende SQL wordt gebruikt om deze datasets op te zetten:
create or replace table date_range_1@inmemorystorage
as
select *
from calendar@datadictionary
where day_date between to_date('01-01-2000', 'DD-MM-YYYY') and to_date('01-01-2015', 'DD-MM-YYYY')
create or replace table date_range_2@inmemorystorage
as
select *
from calendar@datadictionary
where day_date between to_date('01-01-2010', 'DD-MM-YYYY') and to_date('01-01-2020', 'DD-MM-YYYY')
Deze datasets zijn verschillend, maar een eenvoudige SQL-instructie zal hun inhoud in twee richtingen synchroniseren:
- Zorg ervoor dat alle kalenderdatums die voorkomen in date_range_2, ook voorkomen in date_range_1.
- Omgekeerd: zorg ervoor dat alle kalenderdatums die voorkomen in date_range_1, ook voorkomen in date_range_2.
Het eindresultaat is dat zowel date_range_1 als date_range_2 alle kalenderdatums bevatten van 1-1-2000 tot 1-1-2020.
De volgende SQL wordt gebruikt om de datasets te synchroniseren:
synchronize date_range_1@inmemorystorage
and date_range_2@inmemorystorage
identified
by day_date
resolve prefer left
Dat is alles wat nodig is voor een krachtige bidirectionele synchronisatie over één of meerdere apps!
De matching op rijen in date_range_1 en date_range_2 vindt plaats op de inhoud van de kolom day_date.
Er zullen in dit geval geen update conflicten zijn, maar als die er zouden zijn geweest, zorgt de “resolve prefer left” ervoor dat de inhoud van date_range_1 de voorkeur zou hebben gekregen en de inhoud van date_range_2 zou zijn overschreven.
SQL-statement voor synchroniseren en vergelijken
In dit deel laat ik u kennismaken met de nieuwe statements; toekomstige artikelen zullen u voorbeelden laten zien hoe u gegevens kunt synchroniseren tussen datacontainers zoals Exact Online en Outlook, Visma en Outlook en tussen Exact Online administraties.
Deze nieuwe vergelijkings- en synchronisatieverklaringen bieden eenrichtings- en tweerichtingsanalyse en afstemming van gegevens in twee tabellen. Het is een uitgebreide versie van SQL statements zoals ‘upsert’ en ‘merge’ die in andere SQL-implementaties voorkomen, geschikt voor grote volumes en hoge update frequenties die typisch zijn voor grote ondernemingen.
De grammatica kan worden weergegeven als (zie ook Invantive UniversalSQL Grammar (current)):
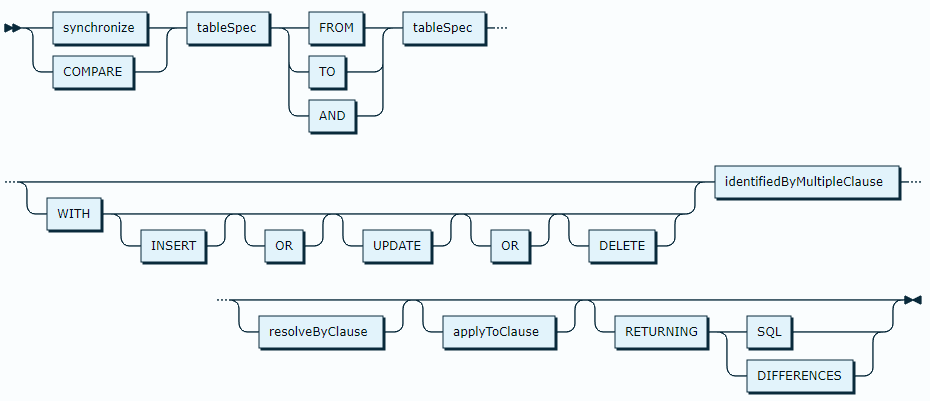
Bij een eenrichtingsaanpak zoals gespecificeerd door “FROM” of “TO” analyseert de vergelijkings- en synchronisatieopdracht typisch de verschillen tussen twee tabellen met identiek genoemde kolommen, waarbij de verschillen worden gesplitst in een van de volgende vier groepen:
- insert: een rij bestaat in de brontabel en niet in de doeltabel;
- delete: een rij bestaat niet in de brontabel, maar wel in de doeltabel;
- update: de rij bestaat in beide tabellen, maar de waarde is verschillend.
- geen: de rij bestaat in beide tabellen en de waarde is gelijk.
Rijen in beide tabellen worden als gelijk herkend op basis van de kolommenlijst zoals gespecificeerd door “IDENTIFIED BY”. De null-inhoud van identificerende kolommen wordt beschouwd als een specifieke waarde voor matching; wanneer zowel de bron- als de doeltabel een null-waarde hebben, horen de rijen bij elkaar.
Na analyse kunnen de verschillen worden gefilterd om alleen het type bewerkingen te bevatten dat met “WITH” is gespecificeerd en vervolgens worden
- toegepast op de doeltabel om de tabellen gelijk te maken, met behulp van bulkbewerkingen waar ondersteund.
- teruggestuurd als een lijst van inhoudelijke verschillen;
- teruggestuurd als Invantive SQL DML-statements om synchronisatie te bereiken.
Na analyse kunnen de verschillen worden toegepast op de doeltabel.
In een bi-directionele benadering, zoals gespecificeerd door het gebruik van het sleutelwoord “AND” tussen de twee tabel-identifiers, worden verwijderingen niet teruggestuurd uit de analysefase en vervangen door inserts op de tabel die de rij van de andere tabel niet heeft. De bepaling van het doel van een bijwerking is gebaseerd op de resolutievoorkeur zoals gedefinieerd door de “RESOLVE”-clausule. De “RESOLVE”-clausule bepaalt ofwel dat updates altijd worden toegepast op de linkertabel of de rechtertabel in hun volgorde met respectievelijk “PREFER LEFT” en “PREFER RIGHT”. Anders wordt de gecombineerde rangorde van de in de “RESOLVE BY”-clausule genoemde kolommen geëvalueerd en wordt de hoogst gerangschikte waarde als leidend beschouwd.