I am trying to extract some elements from a text file (.txt) using a regexp_substr.
I managed to retrieve the content of my file using read_file_text:

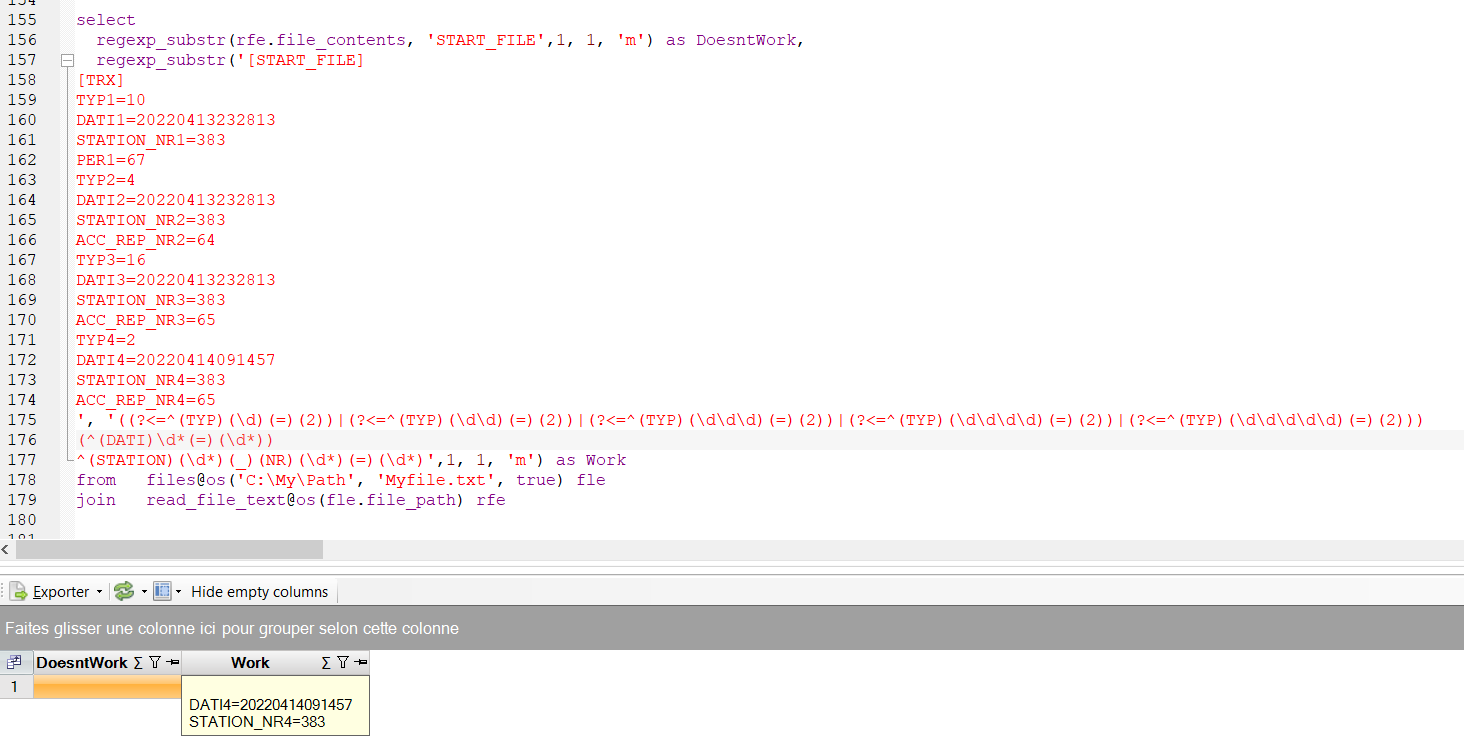
select regexp_substr(rfe.file_contents, 'START_FILE', 1, 1, 'm') as DoesntWork
from Files@os('c:\My\Path', 'Myfile.txt', true) fle
join read_file_text@os(fle.file_path) rfe
Then, in my select, I try to do my regexp_substr on rfe.file_contents. I specify my file, what I want to retrieve, that I want the first occurrence, 1 for appearance and ‘m’ as we have a multi-line file.
However if in what I want to retrieve I put my regex function:
‘((?<=^(TYP)(=)(2))|(?<=^(TYP)(=)(2))|(?<=^(TYP)(=)(2))|(?<=^(TYP)(=)(2))
(^(DATI)\d*(=)(\d*))
^(STATION)(\d*)(_)(NR)(\d*)(=)(\d*)’
or any other regex function asking for more than one character it returns nothing. If, on the other hand, I put a simple ‘\d’ or ‘S’, it works very well.
I have done several tests:
I can lower or upper rfe.file_contents without any problem, regexp_replace has the same problem, it only works on one character, the replace function too. I tried to convert rfe.file_contents using substr and to_char. Nothing works.
I finally succeeded by hard-coding my file into my regexp_substr:
I don’t see what the problem is. I hope you can help me.