Hi,
I’m trying some experimental code to fasten the synchronize statement into Query tool to sync data one way from PostGreSQL to SQL Server.
I’m running the last 20.1.388 Beta.
I first do a full sync of my data with a create or Replace table. I have a sync_table where I store my last update time, so next time I do a sync, I can only update or insert record based on write_date that exists in my PostgreSQL source table t1.
My goal is to prevent the synchronize statement to download 500K records from PostgreSQL and from SQL Server and compare them one by one.
-- first full sync statement
select sysdateutc;
local define JOB_START "${outcome:0,0}";
create or replace table t1@sql
as
select *
from t1@Postgre;
insert into sync_data@sql
( [job_table_name]
, [job_start]
, [job_end]
, [sync_type]
)
Values
( 't1'
, '${JOB_START}'
, sysdateutc
, 'full'
);
then I do an iterative sync by leveraging my last job_start date and the synchronize statement:
-- Incremental statement
select sysdateutc;
local define JOB_START "${outcome:0,0}";
select MAX(job_start) from sync_data@sql where job_table_name LIKE 't1';
local define LAST_JOB_START "${outcome:0,0}";
create or replace table t1@inmemorystorage
as
select *
from t1@Postgre
where write_date > '${LAST_JOB_START}')
;
insert into sync_data@sql
( [job_table_name]
, [job_start]
, [job_end]
, [sync_type]
)
VALUES
( 't1'
, '${JOB_START}'
, sysdateutc
, 'inc'
);
synchronize t1@inmemorystorage
to t1@sql
with insert
or update
identified
by id
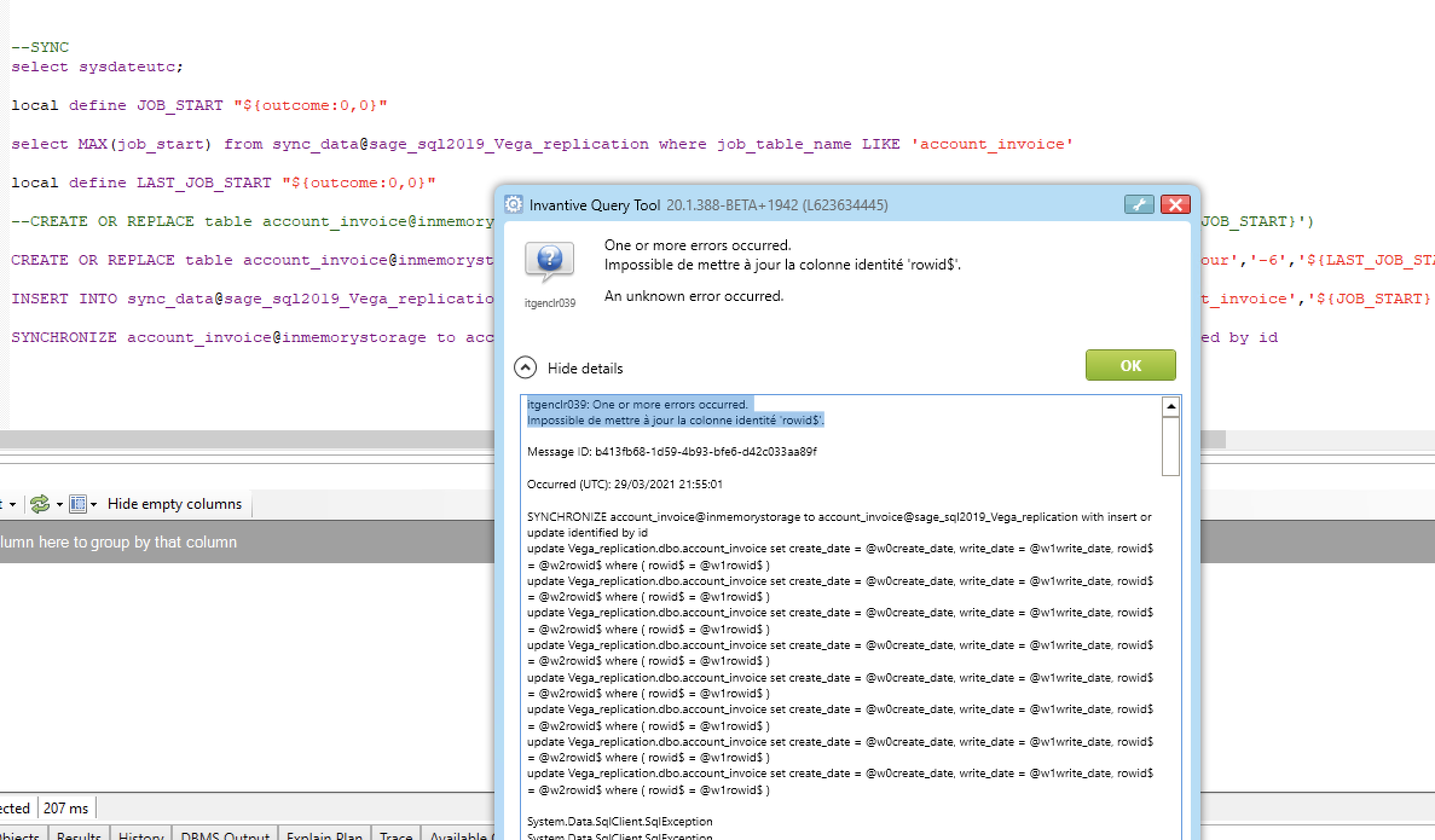
But the last line finds a rowid$ in the t1@sql table created by the create or replace that synchronize is not happy with. I am not able to do a except rowid$ here.
To be added, similar scripting is described here with Incremental replicate Freshdesk to SQL Server
however :
(...)
execute immediate 'create or replace table oldtickets@inmemorystorage as select * except rowid$ from tickets@sql';
execute immediate 'create or replace table tickets@sql as select * from recent_tickets@freshdesk union distinct on id select * except rowid$ from oldtickets@inmemorystorage';
end if;
end;
is not what i would like to achieve because create or replace table oldtickets@inmemorystorage as select * except rowid$ from tickets@sql will load uncessary lot of data that will be erased and re-inserted.
Help appreciated.
itgenclr039: One or more errors occurred.Impossible de mettre à jour la colonne identité ‘rowid$’.Message ID: 12317fc2-16ab-4cbc-993c-bb9c63ba4438Occurred (UTC): 29/03/2021 22:12:57SYNCHRONIZE account_invoice@inmemorystorage to account_invoice@sage_sql2019_Vega_replication with insert or update identified by idupdate Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )update Vega_replication.dbo.account_invoice set create_date = @w0create_date, write_date = @w1write_date, rowid$ = @w2rowid$ where ( rowid$ = @w1rowid$ )