Ik ben bezig met mijn Power BI connectie te switchen van Davista naar Invantive. In principe gaat dat redelijk, buiten behoorlijk priegelwerk.
Echter krijg ik op de dag van livegang van verschillende Power BI gebruikers meldingen dat zij de melding hebben gekregen dat de capaciteit van 2GB werkgeheugen is bereikt. Mijn datamodel is 44mb, mijn grootste tabel is 140k rijen en het probleem doet zich ook voor bij zeer simpele measures. Qua volumes/complexiteit dus absoluut geen issue.
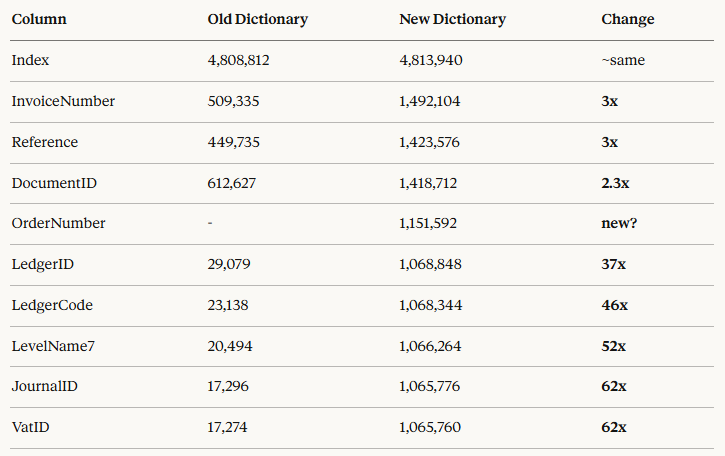
Na wat onderzoek lijkt het te komen doordat de data zoals afgegeven door Invantive enorme verhogingen in dictionary size teweeg heeft gebracht. Hier een overzicht van mijn grootste tabel (old = Davista, new = Invantive):
VatID heeft ongeveer 12 unieke waarden bij beide connectors en zou dus een erg vergelijkbare dictionary grootte moeten hebben. Hebben jullie hier een verklaring en oplossing voor?
Excuses voor de spraakverwarring. Wat betekent het volledige concept “old dictionary” en “new dictionary” uit de afbeelding? Hoe komen die tot stand cq. waar is hier documentatie over te vinden.
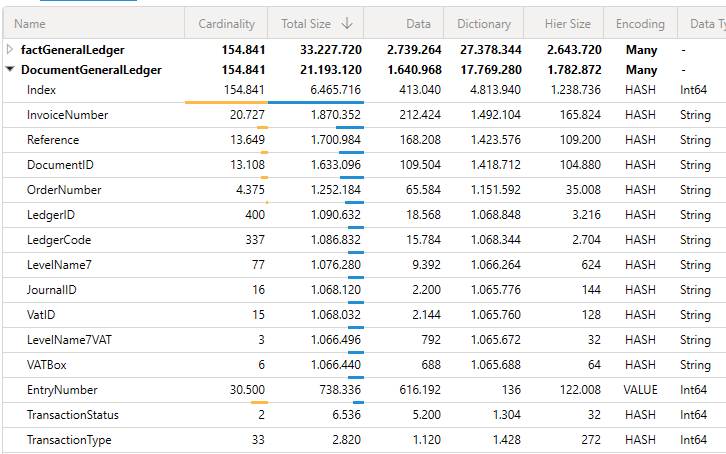
Dit is het resultaat van de VertiPaq Analyzer in DAX Studio. Hieronder de output van de Analyzer. Kolommen met een kleine cardinality hebben giga impact op de totale grootte van de tabel en daarmee het totale model:
Het lijkt me geen toeval dat alle kolommen een vrijwel identieke size hebben van ~ 1.068.000. Dit lijkt alsof er door de feed een vaste overhead wordt meegegeven, ongeacht de dynamiek van de kolom.
De Dictionary kolom in VertiPaq Analyzer toont hoeveel geheugen Power BI intern gebruikt om de unieke waarden van een kolom op te slaan.
Het probleem: wanneer dezelfde data (zelfde waarden, zelfde datatypes, zelfde aantal rijen) wordt ingeladen via Invantive Cloud OData in plaats van via de oude Davista connector, gebruikt Power BI 30-60x meer geheugen per kolom. Dit veroorzaakt ‘Resource Governance’ memory errors bij onze eindgebruikers.
Een concreet voorbeeld — de kolom VatID met 15 unieke tekstwaarden:
Via Davista: 17 KB geheugengebruik
Via Invantive OData: 1.065 KB geheugengebruik
Dit patroon geldt voor alle kolommen, ongeacht cardinaliteit. Kolommen met 3 unieke waarden gebruiken evenveel geheugen als kolommen met 400 unieke waarden (~1 MB per kolom).
Dit wijst erop dat de OData response van Invantive iets bevat — extra padding, metadata, of een andere string-encoding — waardoor de Power BI engine de data minder efficiënt kan comprimeren.
Mijn vraag: zou u kunnen onderzoeken hoe de OData feed de string-waarden teruggeeft? Specifiek: welke encoding wordt gebruikt (UTF-8 vs UTF-16), of er trailing whitespace of onzichtbare karakters worden meegegeven, en of er verschil zit in de OData response formatting ten opzichte van Davista?
Hetgeen beschreven is, is een mechanisme dat Invantive UniversalSQL ook intern veelvuldig toepast om de memory footprint van grote result sets met veel herhaling te beperken.
Er is geen bekend probleem dat de data in verschillende varianten wordt teruggegeven. De OData-feed bevat enkel de registratie, zonder padding of iets dergelijks.
De data van OData is als leesbare tekst in te zien als tekst door de URL bij het verzoek op Invantive Cloud Monitoring te openen via uw browser. De encoding is hierin ook te zien via HTTP headers in de DevTools van Edge, of Chromium-gebaseerde browsers.
Het valt niet uit te sluiten dat dit een beperking van de Microsoft driver is. Mocht zulks het geval zijn, dan zijn er een alternatief alternatieven:
Gebruik een Power BI-omgeving die niet beperkt is door de 32-bits geheugengrens.
Vergelijk de memory footprint met de TDS (Microsoft SQL Server) access point van Invantive Cloud momenteel in BETA.
Beperk het aantal rijen en/of kolommen.
Meld het probleem bij Microsoft.
Mocht u onverhoopt voor gelijke waardes (tekst, getal, GUID of anderszins) toch verschillende representaties kunnen vinden in de OData-feed, gelieve dan een paar voorbeeld toe te voegen inclusief vermelding van de tabel en kolomnamen.
Dankjewel voor de reactie. Ik had al zo’n vermoeden dat als dit daadwerkelijk zo door jullie werd aangeleverd jullie hier vaker problemen mee hadden gehad. Ik zal het met Microsoft opnemen, al vrees ik dat zij niet zo snel en behulpzaam zijn als jullie
Dank voor het uitgesproken vertrouwen in onze dienstbaarheid. Het lukt niet altijd en soms gewoon ook niet, maar intentie is om zo goed mogelijk van dienst te zijn.
Alhoewel het scherm ons niet bekend was, deelt Invantive UniversalSQL wel een groot aantal concepten met Power Query. Hier vallen ook aantal technische elementen onder. Beiden draaien op een PC met Microsoft .net. Binnen Microsoft .net is elke tekst (“string”) anders, ook al hebben meerdere dezelfde waarde. Hetzelfde geldt voor veel andere datatypes.
Het delen van waardes is mogelijk op verschillende manieren, maar vereist eigenlijk altijd een bewuste afweging bij de programmeur. Het verkeerd afwegen kan grote nadelige gevolgen hebben zoals memory leaks. Meer uitleg over dit concept is te lezen in:
De UniversalSQL-engine zal in het algemeen een zeer beperkt aantal waardes vast en centraal onthouden als bekend is dat ze vaak terugkomen. Denk aan constante, bedrijfsnamen e.d.
Daarnaast werkt de engine met result set. Deze zijn in het algemeen gebaseerd op "sparse arrays’, dus een reeks van waarden die samen de niet-lege waarden beschrijven in een rij. “Sparse” omdat er “gaten” in zitten om het geheugengebruik bij tabellen met duizenden (veelal lege) kolommen te beperken.
Bij een result set hoort meestal een reeks van gedeelde objecten. Bijvoorbeeld teksten worden hier centraal onthouden, zodat bij herhaling enkel een verwijzing hiernaar nodig is. Op allerhande wijzen worden in de verwerking deze reeksen van gedeelde objecten gecomprimeerd en vrijgegeven. Een historisch voorbeeld laat de voorbeelden zien: een query result set die 4,5 terabyte aan data bevatte door een tikfoutje van de schrijver dezes paste in 32 GB werkgeheugen.
Deze werkwijze borgt ook dat het onwaarschijnlijk is dat er aan de outputzijde verschillende teksten uitkomen; ze delen dezelfde basis.
Power Query lijkt een soortgelijk mechanisme te gebruiken bij het toepassen van joins, hetgeen schijnbaar als “hash join” geimplementeerd is. Dit is ook 1 van de joinstrategieen binnen UniversalSQL, maar UniversalSQL kent ook een zogenaamde “nested loop join”. Via bijvoorbeeld de SQL hint join_set kan ook gewisseld worden.
Bij het vullen van een vertaaltabel (“dictionary”) met hashes, is het nodig dat tijdens het toevoegen gekeken of een waarde al bestaat. Dit is niet altijd triviaal in Microsoft .net.
Deze vraag is automatisch gesloten na 1 week inactiviteit. Het laatste gegeven antwoord is gemarkeerd als oplossing.
Gelieve een nieuwe vraag te stellen via een apart topic als het probleem opnieuw optreedt. Gelieve in de nieuwe vraag een link naar dit topic op te nemen door de URL er van in de tekst te plakken.