Momenteel halen wij middels Azure Data Factory een aantal tabellen van Exact Online op via OData. Deze schrijven wij nu weg als .csv bestanden op Azure Blob Storage. Vervolgens halen we deze bestanden op met Power BI. Nu zijn er echter .csv bestanden die verkeerd geformatteerd worden doordat er tekens zoals \n en \r voorkomen in bepaalde kolommen. Is er een manier om de OData URL te configureren dat deze tekens al direct vervangen zijn door een spatie? Zo niet, in welk data format (anders dan .csv) kunnen we het beste de tabellen opslaan zonder we problemen krijgen bij het inlezen in Power BI?
Het gebruik van het CSV-formaat kent wat beperkingen en dat zal bij Power BI niet anders zijn.
Mogelijk kan de inhoud van de CSV-bestanden geescaped worden waar nodig, maar dat hangt er van af welke code of ingekochte software gebruikt wordt voor het omzetten van OData naar CSV. De documentatie van csvtable die Invantive SQL biedt voor het uitlezen van CSV-bestanden biedt mogelijk aanknopingspunten of RFC 4180.
Mocht het niet mogelijk zijn, dan zijn JSON en XML alternatieven om te overwegen. Deze bieden ook betere ondersteuning voor afwijkende charactersets.
Daarnaast kan het kostentechnisch met dit abonnement erg aantrekkelijk zijn om niet Azure Data Factory te gebruiken, maar Invantive Data Hub om snel en eenvoudig grote aantallen CSV-bestanden te maken uit Exact Online. Hierbij kan meteen ook de opmaak juist ingesteld worden; hetzij met juiste escaping, hetzij met vervangen bijzondere tekens door spatie.
Het escapen van CSV-bestanden middels Azure Data Factory is tamelijk duur. Vandaar dat we hier weg van willen blijven en het anders willen oplossen.
Waar zou ik documentatie kunnen vinden over het gebruik van ‘csvtable’?
Hoe verschilt Invantive Data Hub van de oplossing die we nu gebruiken en kunnen we zomaar overstappen?
Wordt het opslaan in een ander format dan csv aangeraden? Er kan bv. ook opgeslagen worden in parquet, avro of orc.
Qua andere formaten ontbreekt het bij ons aan serieus te nemen praktijkkennis. Incidenteel komt de vraag voorbij, maar als gaat om echt veel data uit een database of dataset dan raden we aan om via een kort consult hiernaar te laten kijken.
In jullie specifieke abonnement zit het gebruik van Invantive Data Hub en Data Replicator inbegrepen. Het is Invantive SQL-compatible met de andere producten, maar gericht op datavolumes van ruim boven 1 terabyte. Overstappen is eenvoudig, maar dat hangt ook af van de vereiste veranderingen elders in de verwerkingsketen.
De documentatie van CSVTABLE voor het uitlezen van een CSV-file is te vinden op:
Voor zekerheid: csvtable is inputzijde. Voor output kan bijvoorbeeld csvencode of zelf coderen in Invantive SQL gebruikt worden met bijvoorbeeld Invantive Data Hub. Voorbeeld voor bestanden tot pakweg 1 GB met Invantive Query Tool of Invantive Data Hub:
--
-- Option 1:
-- Invantive SQL does the heavy lifting.
--
select listagg
( csvencode(dummy_string || chr(13))
|| ',' || csvencode(dummy_string || '"')
|| ',' || csvencode(dummy_string)
, chr(13)
)
csvpayload
from dual@datadictionary
join range(10)@datadictionary
--
-- Export to CSV file without header using Invantive Script.
--
-- write_file@os or a package is an alternative for exports.
--
local export results as "${system:userdocumentsdirectory}\voorbeeld1.csv" format txt
Resultaat:

Een voorbeeld waarbij Invantive Script de CSV-escaping doet is:
--
-- Option 2:
-- Invantive Script does the CSV-escaping. Invantive Script is only available on
-- on-premises products and not on online products.
--
select dummy_string || chr(13) col1
, dummy_string || '"' col2
, dummy_string col3
from dual@datadictionary
join range(10)@datadictionary
local export results as "${system:userdocumentsdirectory}\voorbeeld2.csv" format csv include technical headers
Resultaat:
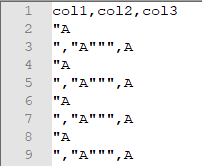
Voor echt grote CSV-bestanden (boven 1 GB) raden we aan om op basis van een kort consult onderstreuning te zoeken.
Deze vraag is automatisch gesloten na tenminste 2 weken inactiviteit nadat een mogelijk passend antwoord is gegeven. Het laatste gegeven antwoord is gemarkeerd als oplossing.
Gelieve een nieuwe vraag te stellen via een apart topic als het probleem opnieuw optreedt. Gelieve in de nieuwe vraag een link naar dit topic op te nemen door de URL er van in de tekst te plakken.