Varchar2
Ik vermoed dat je bedoelt dat Invantive SQL vaak een varchar2 datatype gebruikt. Het varchar datatype wordt principieel nergens gebruikt, dus varchar(2) is onwaarschijnlijk.
Het varchar2 datatype is een variant op het oorspronkelijke varchar datatype binnen de ANSI-standaard. Die laatste staat voor een tekst die met een variabele lengtegebruik opgeborgen wordt in een database.
Het oorspronkelijke varchar datatype hecht een betekenis aan de NULL waarbij het de bedoeling is dat een lege tekst en NULL verschillend zijn. Dit onderscheid kent Invantive SQL niet; een lege tekst is altijd hetzelfde als NULL. Dit is grotendeels vergelijkbaar met het Oracle RDBMS en in tegenstelling tot bijvoorbeeld PostgreSQL. In PostgreSQL zijn '' en NULL twee verschillende dingen. Op Oracle RDBMS zijn NULL en een lege tekst op specifieke implementatiedetails weer wel afwijkend, maar hier heb je op Invantive SQL geen last van.
Een samenhangend issue is dat varchar een andere betekenis hecht aan spaties aan het einde van een tekst. Die blijven behouden, terwijl bij Invantive SQL de ontwerpkeuze gemaakt in lijn met de ideeën achter varchar2 is om die achterwege te laten.
Werkgevers en werkgeverdata
Op Loket kun je werkgevers vinden in Employers. Net zoals NMBRS heeft Loket daaronder een boomstructuur waarbij je steeds verder inzoomt. Onder werkgevers hangen bijvoorbeeld de werknemers, dienstverbanden en afdelingen. Helaas heb ik zelf geen rechten op een Loket test-omgeving met afdeling, maar voor werkgevers kan ik je de werking van een query aan de hand dit voorbeeld illustreren:
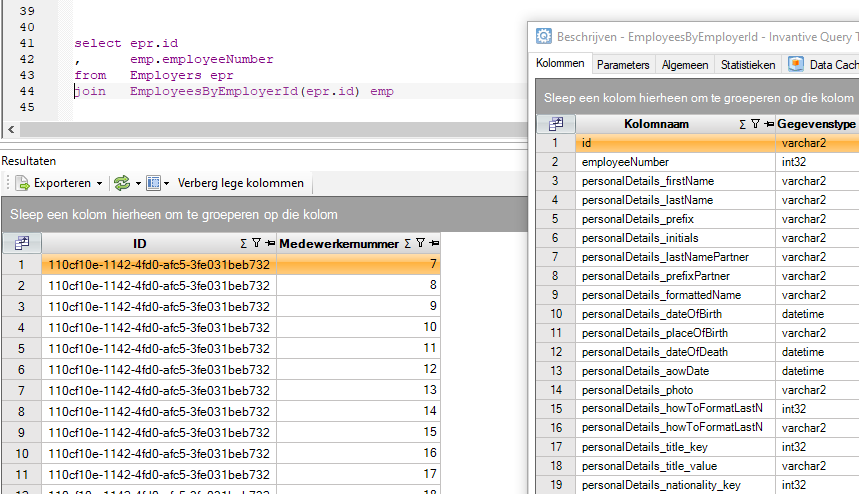
select epr.id
, emp.employeeNumber
from Employers epr
join EmployeesByEmployerId(epr.id) emp
Eerst wordt een lijst van alle werkgevers opgehaald uit de Loket API via employers. Vervolgens wordt van elke werkgever de unieke ID genomen en meegegeven aan de zogenaamde “tabelfunctie” EmployeesByEmployerID. Er wordt dus telkens een query op EmployeesByEmployerID gedaan per werkgever. Als je 6.000 werkgevers verloont, zijn dit dus ook 1 + 6.000 API calls.
De uitkomst vanuit Loket lijkt op:
De meeste tabelfuncties hebben dit formaat en zijn dus feitelijk een soort van join. Er zijn ook andere soorten tabelfuncties op andere platformen, zoals bijvoorbeeld contacts(:searchfilter) waarbij je een zoekpatroon door kunt geven.
Views
Om het leven wat makkelijker te maken en ook om gebruik van Loket data uit Power BI/Power Query mogelijk te maken, leveren we een aantal voorgedefinieerde queries op Loket mee als “views”. BIjvoorbeeld voor werknemers bestaat de view EmployerEmployees. Ze zijn niet altijd even efficient als handmatig geschreven queries maar tot zeg duizend loonstrookjes werkt vrijwel altijd net zo goed als handgeschreven.
De definitie van EmployerEmployees kun je terugvinden in SystemViews@DataDictionary (Data Dictionary views) en is:
select epe.* prefix with 'epe_'
, epr.* prefix with 'epr_'
from EmployersByUser epr
join employeesbyemployerid(epr.id) epe
Helaas is er geen view EmployerDepartments omdat we die op onze ontwikkelomgeving niet kunnen ontwikkelen door ontbrekende modules. Mocht je een omgeving hebben met deze module, dan voegen we die samen met jou graag toe.