De volgende query geeft de JSON van de loonstroken van de dienstverbanden en jaren:
select ppr.document
from PayrollAdministrationPayrollRunPeriodResults pat
join PayrollPeriodResultsByEmploymentIdAndYear(pat.prt_employmentId, pat.prn_payrollPeriod_year) ppr
limit 10
De JSON kun je dan exporteren via bijvoorbeeld:
local export documents in DOCUMENT to "c:\temp" filename automatic
Let op: blindelings bovenstaande query draaien op een Loket-omgeving met 5.000 werkgevers en veel meer werknemers en dienstverbanden duurt heel lang. Daarom is een limit 10 toegevoegd.
Net zoals bij de loonaangiftes richting de BelastingDienst zit er een structuur in de JSON. Hier doet Invantive SQL op dit moment niks; de query moet zelf alles opknippen nadat de specificaties opgevraagd zijn. Bij terugkerende vraag kunnen we overwegen dit opknippen van het document (de “payload”) toe te voegen als een aparte view.
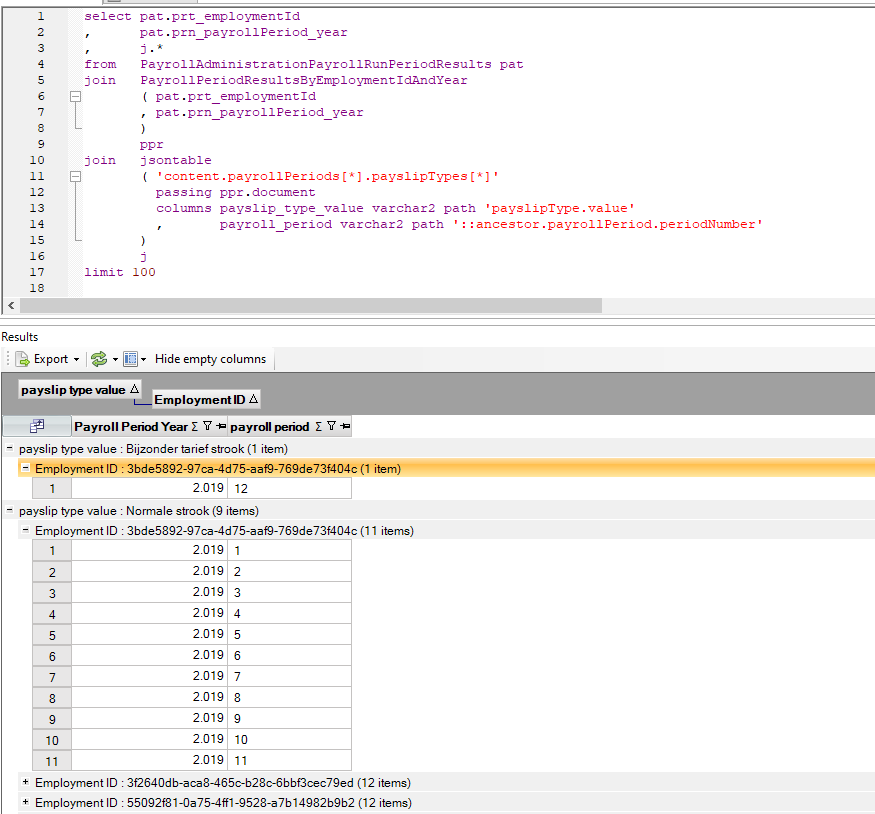
Een klein voorbeeld met minimale informatie vanwege privacy toont het soort loonstrook en de periode (want alleen het jaar wordt meegegeven en daar komen 0 of meer periodes op terug):
Na analyse blijkt dat de metadata de structuur beschrijft. Voor een volgende release kijken we of het lukt om de metadata automatisch te vertalen naar onderliggende tabellen. ITGEN-5331
Wat is de status hiervan? Wordt dit nu door Invantive opgepakt zodat we deze uitgepakt kunnen benaderen vanuit Invantive tool? Of is support afdeling van Loket nodig hiervoor? Kunnen wij iets doen om te versnellen?
Op dit moment krijgen andere activiteiten voorrang om gebruikers te helpen om trickle loading makkelijker te managen. Ik kan geen verwachte beschikbaarheid afgeven.
Kleine/vriendelijke reminder dit op te pakken zodra enige capaciteit beschikbaar is. Voor zowel de Loket sales jongens als voor ons is dit momenteel showstopper om live te gaan en/of te verkopen.