Summary
The ‘union distinct’ set operator of Invantive SQL enables sieving data from multiple sources to find the best match on a real-world object, such as product or company. This note describe the use of the set operator and provides a sample SQL statement.
Choosing the Right Data Set on a Real-world Object or Person
A frequent use case is the rating multiple data sets on the same real-world object or person based upon data quality.
For example, you might have excellent data on your customers in the corporate ERP system, but the data on prospects is less well organized and structured. However, the list of companies available as prospects is may times larger than the list of customers. When available, you prefer to use corporate ERP-based data, but in all cases it is still possible to use the prospect data.
The ‘union distinct set’ operator is an Invantive SQL-specific extension to ANSI SQL, which simplifies choosing the best data set for a specific purpose across a range of possible data sets on the same real-world object or person.
The ‘union distinct on’ set operator operates as a sieve. Whenever a higher rated data set has information on an object, that one is preferred. However, less rated data sets are all considered in their order. In general, the preferred source of a set of data is listed first, followed by one or multiple ‘union distinct on’ set operators, each with a data set of less preference.
In traditional SQL, you could either use grouping with a window when available or a apply a union with a group by. The ‘union distinct’ set operator especially shines with a great performance in high-volume scenarios and when the star (‘*’) selector is used since it reduces the maintenance effort on data model changes.
Sample Sieving Data
The following query takes credit rating data from four data sets:
- active customers: the company ordered a product in last year and paid in time.
- inactive customers: the company ordered a product before last year and paid in time.
- prospect: the company never ordered, but data indicates a good credit behavior.
- random: the company was never involved in a purchase process. The credit rating is defaulted to a value of 5.
A full list of all data sets is:
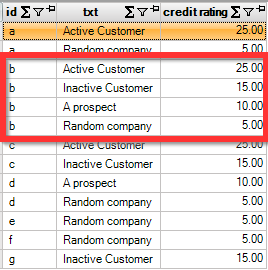
The customer with id ‘b’ is registered in four data sets, but for the credit rating the value of 25 should be used.
The outcome should have one value per customer, such as:

The SQL query to achieve this result uses ‘union distinct on’ as follows:
select corporate_erp.value id
, 'Active Customer' txt
, 25 credit_rating
from string_split('a,b,c', ',') corporate_erp
union distinct on id
select corporate_erp_but_inactive.value id
, 'Inactive Customer' txt
, 15 credit_rating
from string_split('b,c,g', ',') corporate_erp_but_inactive
union distinct on id
select crm_prospect.value id
, 'A prospect'
, 10 credit_rating
from string_split('b,d', ',') crm_prospect
union distinct on id
select public_source.value id
, 'Random company'
, 5 credit_rating
from string_split('a,b,d,e,f', ',') public_source
order
by id
Grammar
The grammar of the ‘union distinct’ operator is given below:
