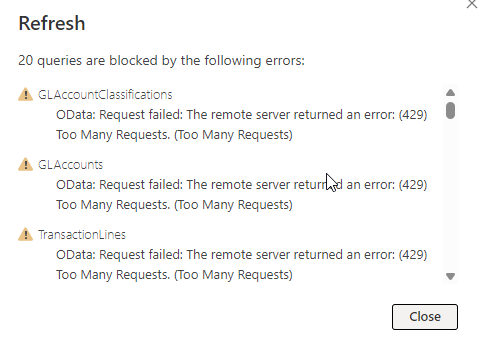
Waar gaat dit mis? We hebben amper iets aangepast aan in de Azure Data Factory. We hebben de meeste query’s geoptimaliseerd, zodat deze zo weinig mogelijk data ophalen.
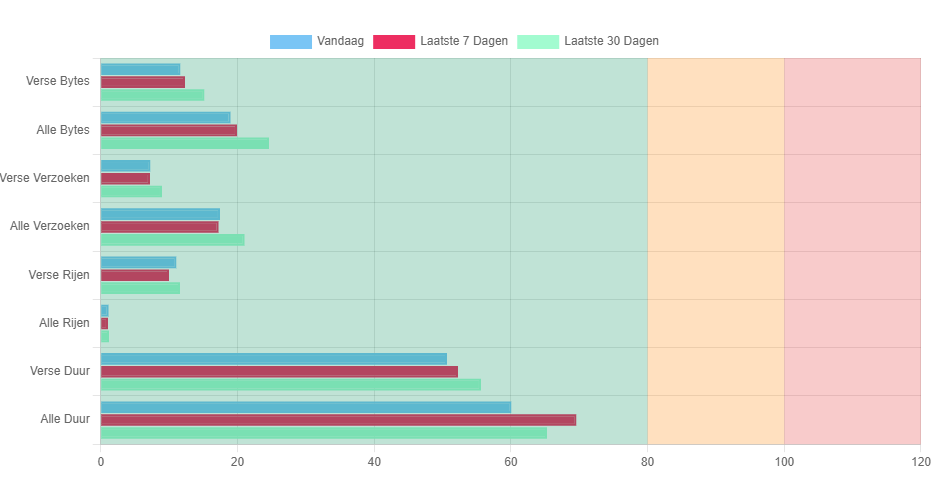
In deze afbeelding valt op dat de “Alle Duur” ongeveer twee keer zo lang is als “Verse Duur”. Dit betekent dat er 50% reductie te bereiken is door dezelfde data niet meerdere keren opnieuw op te halen.
Hoe wordt de grafiek opgebouwd? Waar wordt de waarde van ‘Alle Duur’ door bepaald? Hoe kunnen we de ‘Alle Duur’ tijd verlagen? Door de cache waarde te verhogen?
Bij controle blijkt dat de berekeningswijze momenteel niet klopt: de waarde bij “Alle” is tweemaal de waarde van “Vers” en 0-maal de waarde van “Cache”. Een correctie hiervoor zal naar verwachting binnen 1 werkdag in productie genomen worden op Invantive Cloud. De waarde bij “Alle” wordt dan voortaan eenmaal de waarde van “Vers” en eenmaal de waarde van “Cache”.
Voor gebruikers die relatief vaak data uit cache halen kan dit betekenen dat de Fair Use-waardes overschreden worden, voor gebruikers die dat relatief weinig doen kan dit betekenen dat de metingen weer onder de Fair Use-waardes komen.
Advies is om na in productie name nogmaals afbeelding van bijgewerkt dashboard toe te voegen.
Dankjewel voor deze duidelijke uitleg. Wij zullen morgen en overmorgen een nieuwe afbeelding van het bijgewerkte dashboard aan deze forumpost toevoegen
Bedankt voor het achterhalen van het probleem! Is het mogelijk om ergens de huidige cachewaarden in te zien? Daarnaast zouden we graag willen vragen of de limieten voor vandaag kunnen worden verhoogd, zodat we onze dagelijkse werkzaamheden zonder onderbreking kunnen voortzetten. Zie de afbeelding hieronder voor meer context.
Er is een nieuwe release beschikbaar die dit probleem zou moeten oplossen. De benodigde wijzigingen zijn beschikbaar vanaf release 24.0.314 en in alle toekomstige BETA versies.
Deze nieuwe release is productie genomen op Invantive Cloud.
Cached data van Bridge Online/App Online naar buiten is herkenbaar aan de waarde BridgeOnlineOdata4ZipOutCache voor Data Container Alias in het scherm Sessie I/O’s. Verse data van Bridge Online/App Online naar buiten is herkenbaar aan BridgeOnlineOdata4.
Een tijdelijke verhoging is gedurende productie-uren praktisch niet meer mogelijk vanwege de impact van de benodigde aanpassingen.
Echter, met de livegang van de nieuwe release zijn vanwege de benodigde herstart de limieten aangepast en tijdelijk verdubbeld tot 200% vooraleer verbindingen afgebroken worden met een 429 HTTP-code.
De verdubbeling tot 200% voorkomt dat zonder enkele dagen voorafgaande zichtbare waarschuwing in het dashboard verbindingen wegvallen omdat in plaats van de verse data de cached volumes (met mogelijk hogere waardes) gebruikt worden.
In de loop van de komende week zal deze tijdelijke verhoging weer ongedaan gemaakt worden.
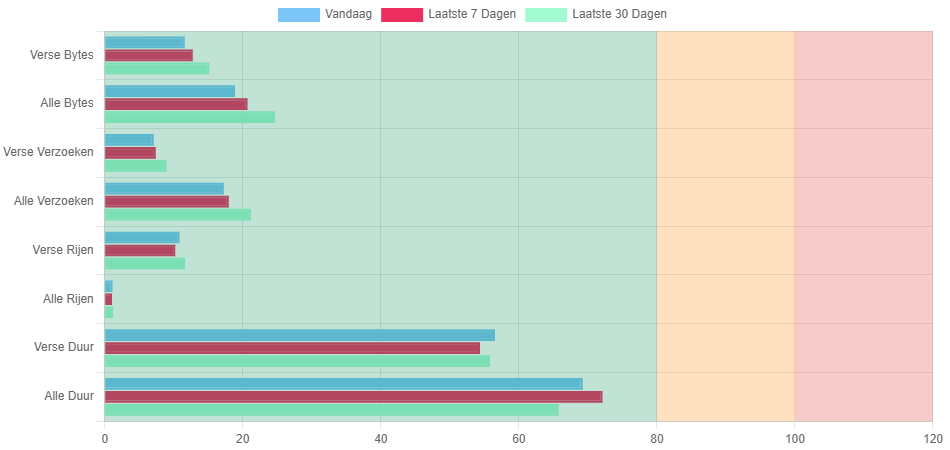
Zo te zien heeft jullie aanpassing van de totale duur berekening gewerkt. Vannacht heeft onze Data Factory 0 errors gehad m.b.t. ‘Too many requests’. We hebben ook de waardes van de HTTP Disk Cache Maximum Leeftijd (sec) en de Bridge Response Cache Maximum Leeftijd (sec) verhoogd voor iedere database. We zullen dit monitoren en een update plaatsen nadat de verdubbeling weer ongedaan wordt gemaakt.
Dank voor update. Fijn te zien dat het dubbel gebruik van data uit cache al relatief beperkt was; de optimalisatie waren wat dat betreft al goed ingeregeld.
Excuses voor het ongemak door de dubbeltelling van verse duur in plaats van optellen verse duur plus duur data uit cache.
Ook vannacht zijn er geen errors opgetreden. Voor nu zal deze oplossing prima werken. Mochten we in de toekomst nog ergens tegenaan lopen dan zullen we tegen die tijd wel een seintje geven.
Mocht er geoptimaliseerd moeten worden, dan is advies om op “Verse Duur” te sturen, bijvoorbeeld door te kijken welke snellere alternatieven er zijn voor een bepaalde bewerking.
Vanuit Invantive zal het mechanisme beschreven in SQL execution steps ook op termijn gebruikt gaan worden om het CPU-gebruik en logging-gebruik nauwkeuriger te gaan bepalen waardoor op termijn “duur” zelf kan verdwijnen. “Duur” is een minder nauwkeurige schatting van de kosten van een faciliteit omdat tijdsduur van een request kan varieren afhankelijk van de belasting van de infrastructuur zonder dat het request daadwerkelijk meer of minder kosten veroorzaakt.