Summary
Invantive SQL and PSQL offer extensions to execute native requests, being it either HTTP or SQL requests, on the backing platform of every data container in a distributed database. This note introduces the process flow and the SQL optimizer. After that samples are shown using SQL with scalar native requests with one result and using PSQL with scalar one value, row-level and set-based results.
Global SQL Database
Invantive SQL enables you to create a global database spanning data sources across the globe. Each data source connection is named a “data container”. Each global database defines a number of data containers being either:
- file-based such as XML, JSON, CSV or Excel;
- traditional SQL-based such as Oracle or PostgreSQL;
- cloud-based such as Exact Online or Company.info.
The Invantive SQL engine translates SQL statements into operations applicable for the platform. For instance, a SQL-select on one file-based source such as a Payroll Audit File is translated into:
- interpreting the XML’s metadata,
- matching the data model on the metadata,
- reading and parsing the file contents,
- filtering the appropriate result set.
But a SQL-select on Exact Online would not translate into file operations but into XML and OData-based operations. SQL statements can also combine multiple data sources in one SQL-select statement. Finally, depending on the platform’s capabilities, data can be changed and the data model can be altered on the data source by using Invantive SQL statements.
SQL Optimizer
Some Invantive SQL installations handle relational data in terabyte range. With such an amount of data, a simple brute force approach on the execution of SQL statement does not yield results in this lifetime, so a so-called “optimizer” assists our Invantive SQL engine. The optimizer assists the Invantive SQL engine in choosing the best execution approach for SQL statements from the various possibilities. “Best” is defined in terms on restricting the execution approach by minimizing on one or multiple dimensions such as execution time, disk I/O or network.
Talk Native
The platforms the data containers run on offer capabilities that Invantive SQL has no representation or maybe never ever will have due to conflicts with the design vision behind Invantive SQL. For example, the PostgreSQL platforms offers arrays as a data type, but our current vision on arrays is that these represent logically records, so a separate logical table would be a more logical choice as we see things currently. The same holds for some features of other platforms such as Oracle, Exact Online or Company.info.
Nonetheless, keeping PostgreSQL as a running example, the possibility to use such specific features opens new inroads to help you further achieve your design goals being it either scalability, maintainability, compatibility or whatever. Therefore Invantive SQL offers support both in SQL and Procedural Options to “talk native” to the platform.
For cloud-platforms, this typically translates into using the same data transfer channel for API requests to execute carefully hand-written HTTP requests. For SQL-based platforms, this enables you to directly execute the platform’s own SQL syntax without any translations, verifications and handling by Invantive SQL.
Native with Invantive SQL
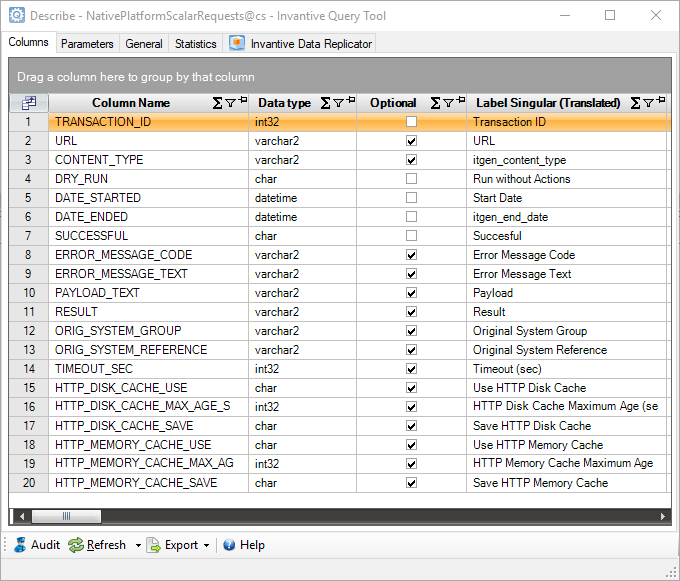
For use within Invantive SQL, there is a table named NativePlatformScalarRequests associated with every data container.
Insert actions into the NativePlatformScalarRequests table result in the payload being transported and executed on the platform associated with the data container.
The available fields are:
A typical native request for an ANSI SQL-based data container might be:
--
-- Remove all rows in the unaggregated table with a creation date
-- before the last created row in the aggregated table.
--
insert into NativePlatformScalarRequests@DATA_CONTAINER_ALIAS
( payload_text
)
values
( 'delete from unaggregated where date_created < ( select max(date_created) from aggregated)'
)
The insert on the native platform requests delays till the requested native request has finished. The table NativePlatformScalarRequests when queried afterwards will contain one row for every request, including the results and whether it executed successful. The ORIG_SYSTEM_REFERENCE column can be used as a provided primary key to find the right row.
By default, an error raised by the platform during execution of the request does not bubble up to Invantive SQL. Your code will need to check the contents of the table NativePlatformScalarRequests to determine the outcome and possible appropriate action.
The use of the columns URL, CONTENT_TYPE and the columns whose names start with HTTP_ are for use with cloud-based platforms.
Native with Invantive PSQL
Within Invantive PSQL you can of course use NativePlatformScalarRequests as in Invantive SQL. But Invantive PSQL also provides integrated procedural features to execute native requests.
For simple scalar or record-level requests, you can use the execute native statement. In the following sample, a native PostgreSQL SQL-query is run using PSQL. The query returns one or more scalar values which are memorized in PSQL variables:
create table runs@inmemorystorage
( outcome date
)
declare
l_native_date_retrieved date;
begin
execute native 'select (now() + interval ''4 hours'')::date'
into l_native_date_retrieved
datacontainer 'DATA_CONTAINER_ALIAS'
;
insert into runs@inmemorystorage
( outcome
)
values
( l_native_date_retrieved
);
end;
select * from runs@inmemorystorage
For native queries that returns multiple rows of data, PSQL offers an extension to the for…loop…end loop statement.
When the native SQL returns rows, they are processed on a row-by-row basis, just as with a normal for…loop…end loop statement:
( outcome datetime
)
begin
for r in ( execute native 'select now() c union select now()::date c' datacontainer 'DATA_CONTAINER_ALIAS')
loop
insert into runs@inmemorystorage
( outcome
)
values
( r.c
);
end loop;
end;
select * from runs@inmemorystorage
The output will resemble the following image:
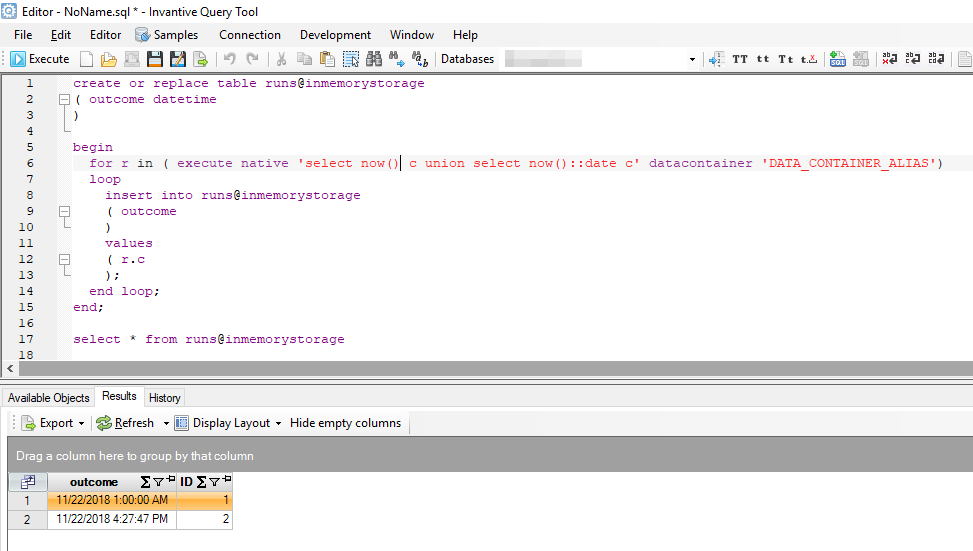
Please note that the first row of the results is dated at 1 AM instead of 12 AM. In this scenario, Invantive SQL was running one timezone away for the database server executing the native SQL statement. A timezone compensation was made along the route, but in general it is technically less demanding to restrain from such complex scenarios in your applications.
Execute native procedural SQL with output
Many traditional database platforms provide a way to return results using print statements. For instance on Oracle, the following Oracle PL/SQL prints ‘hello world’ to a dbms_output-enabled SQL client such as SQL*Plus or TOAD:
begin
dbms_output.put_line('hello world');
end;
Such procedural SQL on the backing platform can also directly be executed using execute native, while the output is gathered and printed by Invantive SQL client products.
Use the following statement to execute the previous sample directly from Invantive PSQL:
begin
execute native 'begin dbms_output.put_line(''hello world''); end;' datacontainer 'ora';
end;
Typical output is:
01-01-1970 08:41:20.35012 PRINT hello world