Notubiz is een oplossing voor raadsinformatiesystemen met als visie om het politieke proces zo transparant mogelijk te maken. Vergeleken met andere aanbieders is Notubiz verder qua transparantie.
Ophalen Notubiz gebruikers via API
Notubiz heeft een API die momenteel nog niet openbaar gedocumenteerd is. Toch kom je met een beetje proberen al best ver, zeker met dit voorbeeld van Willy Tadema. Via de Notubiz API kun je een lijst van Notubiz-organisaties opvragen. De basis is de organisations-API die te vinden is op https://api.notubiz.nl/organisations.
De lijst van Notubiz-organisaties krijg je dan met de volgende query:
select xml.*
from HTTPDOWNLOAD@DataDictionary
( 'https://api.notubiz.nl/organisations'
) htp
join xmltable
( '/result/organisations/organisation'
passing htp.content_clob
columns id integer path '@id'
, latitude number path '@latitude'
, longitude number path '@longitude'
, last_change integer path '@last_change'
, name varchar2 path 'name'
, logo varchar2 path 'logo'
) xml
De API’s bieden versionering via de parameter version maar die is niet verplicht op deze API. Ook kun je output in JSON opvragen, maar voor dit voorbeeld hebben we de XML gebruikt.
De uitvoer van de organisations API van Notubiz ziet er als volgt uit:
<?xml version="1.0" encoding="UTF-8"?>
<result>
<organisations>
<organisation id="262" latitude="51.908269" longitude="4.340947" last_change="1603364292">
<name><![CDATA[Gemeente Vlaardingen ]]></name>
<logo><![CDATA[https://logos.notubiz.nl/gemeente_vlaardingen.PNG]]></logo>
</organisation>
<organisation id="264" latitude="51.559568" longitude="3.501400" last_change="1595535311">
<name><![CDATA[Gemeente Veere ]]></name>
<logo><![CDATA[https://logos.notubiz.nl/gemeente_veere.PNG]]></logo>
</organisation>
De bovenstaande query haalt daarom eerst via httpdownload de inhoud van de pagina op. De tekstuele representatie daarvan staat in het veld content_clob.
Vervolgens knippen we de XML op in een herhalende reeks van gegevens met de XPath expressie /result/organisations/organisation. Per organisatie krijg je dan een fragment XML met de gegevens van de organisatie. In de columns clause worden deze velden opgeknipt naar een kolommenstructuur.
Ook bij het splitsen van de XML in velden wordt gebruik gemaakt van XPath. De notatie met @ staat voor de waardes van attributen, terwijl de XML elementen via bijvoorbeeld name worden opgevraagd.
Eindresultaat is een lijst van alle Notubiz-organisaties:
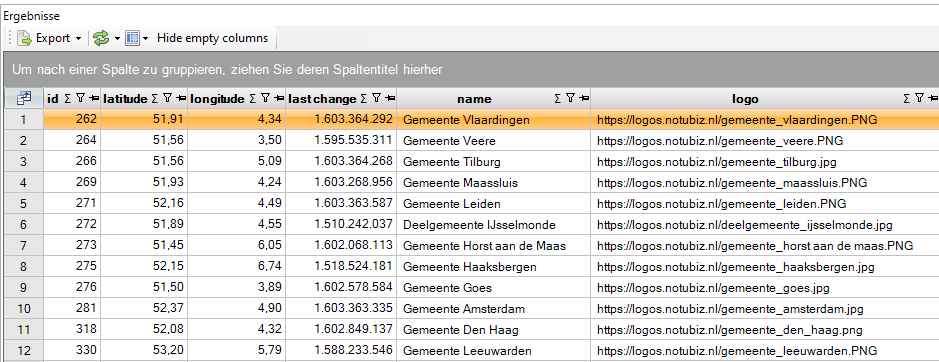
Merk op dat hierin ook Belgische overheden kunnen voorkomen; Notubiz is ook actief in Vlaanderen.
Websites relateren aan Notubiz-gebruikers
Helaas biedt de organisations API van Notubiz geen bekende mogelijkheid om de URL’s te bepalen waar de organisaties hun politieke proces zichtbaar maken. Echter, alle websites lijken actief achter het gedeelde IP-adres 195.20.144.219 en via een reverse IP-lookup naar domeinnamen zijn vlot een groot aantal websites te achterhalen. Hierbij blijkt dat er eigenlijk vier varianten zijn:
- raadsinformatie.nl: de voorkeurssite van de meeste Nederlandse gebruikers
- notudoc.nl: een oude variant die niet meer in gebruik zal zijn getuige het verlopen certificaat
- notubiz.nl: nog in actief gebruik door een paar Nederlandse gebruikers
- notubiz.be: de Belgische gebruikers
Iedere hoofdpagina van de websites heeft een vergelijkbare structuur met daarin onder andere de organisatie ID die ook gebruikt wordt in de organisations API:
<meta class="site" data-organisation-id="2431" />
en de naam van de organisatie
<h1 class="skip_link">Heist-op-den-Berg</h1>
Merk op dat het gebruik van een opnummerende ID concurrenten van Notubiz ook inzage kan bieden in de churn en commerciële succes in nieuwe markten.
Met de volgende query kunnen we voor de bekende websites de relaties leggen naar de inhoud van de organisations API:
select ste.url
, htable.*
from sites@db ste
join HTTPDOWNLOAD@DataDictionary
( ste.url
, diskCache => true
, diskCacheMaxAgeSec => 31 * 86400
--
-- Sometimes a Notubiz site is down and returns HTTP 500 status,
-- such as today Apeldoorn.
--
, ignoreWebError => true
) htp
join htmltable
( '//meta[@class=''site'']'
passing htp.content_clob
columns org_id varchar2 path '@data-organisation-id'
)
htable
where ste.crawl_type='notubiz'
order
by ste.url
De werking is vergelijkbaar als met de eenvoudige XML API eerder gebruikt:
- de lijst van websites wordt opgehaald met URL,
- per website worden de HTML gegevens opgehaald van de hoofdpagina,
- tenslotte wordt via
htmltablede organisatie ID opgehaald.
De htmltable zoekt naar een herhalende reeks binnen elke HTML-pagina na het ontleden hiervan. De reeks is een <meta> tag op willekeurige diepte met als eigenschap class='site'.
De lijst van Notubiz websites met hun bijbehorende organisatie ID ziet er ongeveer als volgt uit:
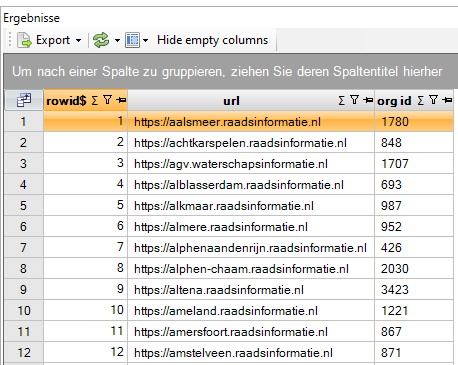
Helaas kan niet van alle organisaties zo achterhaald worden wat de website is, dus enig handmatig speurwerk blijft van toepassing.