The Exact Online REST API provides so-called “sync APIs.” Sync APIs are new REST APIs that solve some of the disadvantages when using Exact Online webhooks for incremental replication.
Exact Online’s sync APIs are a welcome improvement for environments based on Invantive Cloud or the Excel add-in Invantive Control:
- Easy to use: the sync APIs are easy to use and work right the first time.
- More reliable: the chain of dependencies is much shorter compared to webhooks. The failure-prone sending and distribution of change messages via Exact Online webhooks is omitted.
- Fewer API calls: the sync APIs significantly reduce the number of API calls for large Exact companies.
- Efficient: resource usage is measurably lower.
- Economical: the sync API tables are available with any Invantive Office subscription and even with Invantive’s free Power BI connector for Exact Online.
More background information can be found in Exact Online sync APIs.
For each available sync API for Exact Online, there is an associated table in Invantive SQL that represents the complete content. For example, for Items (articles) this is the table ItemsIncremental.
The fields of sync API tables such as ItemsIncremental are almost identical to the original table (here ItemsBulk). However, derived fields such as ItemGroupDescription have been removed. The incremental nature of ItemsIncremental necessitates the use of a normalized data model. For correct reporting, the related tables should be linked in, for example, the Microsoft Power BI data model.
Update frequency of sync REST API tables.
The data of a sync API table is automatically updated when a table based on the sync APIs is used in a query. The default caches in memory and on disk are not used.
Querying executes smooth. A query on Exact Online that retrieves less than 1% of the data often remains faster by formulating a query on the normal API with appropriate filters in the where-clause. In that scenario, Invantive SQL’s automatic optimizer ensures that a smart filter is compiled and passed to Exact’s API servers. As a result, for example, the right 10 items within a million items are then found and retrieved from a few hundred million.
Using incremental tables
Using the incremental tables for Exact Online is easy.
With Invantive SQL you can retrieve the current and updated items list for all selected Exact companies using, for example:
select *
from ItemsIncremental@eol
In the Invantive Cloud editor this looks like:
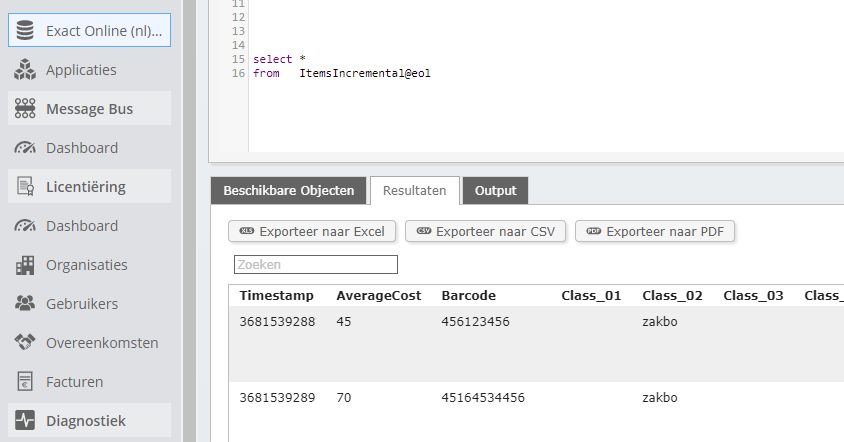
For Microsoft Power BI, Microsoft Power Query and other OData4 consumers, selection of the table name is sufficient.
Analysis Operation of Sync APIs
Although the sync APIs have a much simpler structure than the webhooks used for Trickle Loading, sometimes there may still be reason to check the correctness. Therefore, Invantive SQL provides a number of analytical views for the Exact Online sync APIs:
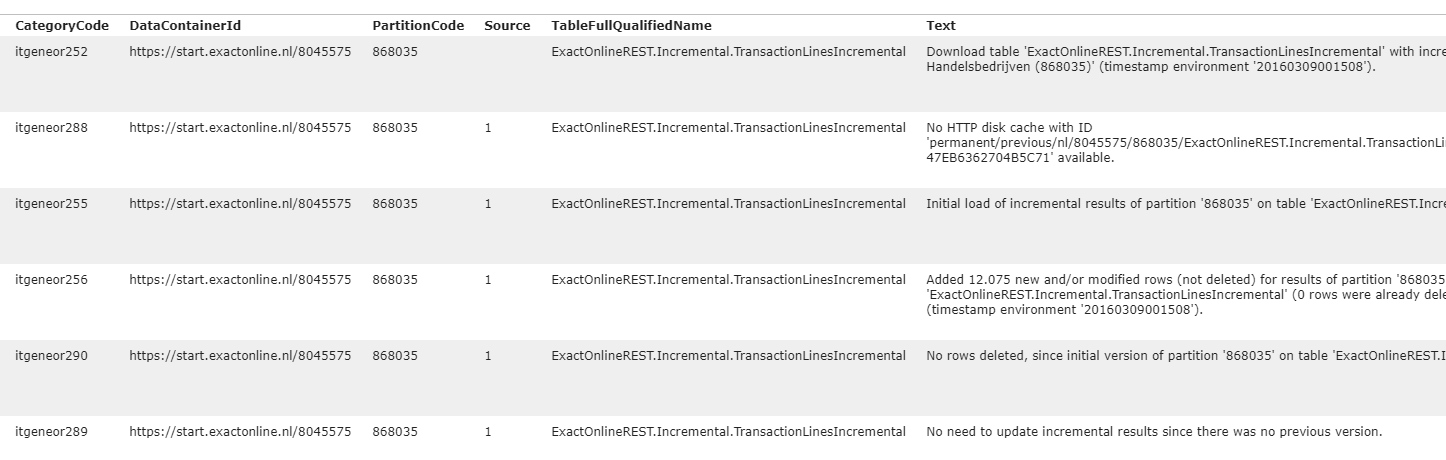
IncrementalLoadStatuses: the status per table and company.IncrementalLoadStatistics: statistics such as number of deleted rows and rate per change in status for tables and companies.IncrementalLoadEventLogEntries: textual notifications for each mutation in the status for tables and companies.
For example, the query select * from IncrementalLoadEventLogEntries shows:
Performance.
The performance of queries on incremental tables is roughly a factor of five better than the original queries for small tables. The factor may vary because performance is determined primarily by network speed and the speed of the local PC or server, whereas previously the speed of the Exact Online API-servers determined the speed.
For large tables with 500,000 or more rows, the performance gain increases to about 25x faster. For example, retrieving 1.4 million transaction lines via TransactionLinesIncremental normally takes about 75 minutes and takes 3 minutes with the *Incremental-variant.
Why are the derived columns missing such as general ledger account description?
The new tables only contain fields that are also stored in the Exact Online database. For example, for a general ledger account, only the unique key of the general ledger account will be present. Derived data such as the general ledger account description must be retrieved by establishing a relationship in a Power BI data model or using a view. In technical terms, the table is “normalized” to the Exact Online’s internal data model.
The absence of derived columns has several advantages:
- the data volume is reduced,
- in Power BI, the data model is correct by design.
People often ask about the “why”; the predecessors of the new sync API tables did contain the derived data. The reason is most likely due to the fact that Exact uses so-called “database triggers” in their database for these sync APIs. A database trigger executes a small piece of code when there is a change. However, to make a change in the description of a general ledger account also register changes in all places where that general ledger account is used will be more complex and require many times more resources. After all, a general ledger account can be used in millions of entries. This is probably why the propagation of changes to a row across the entire data model, possibly across dozens of tables and hundreds of thousands of related rows, was abandoned.
Releases
As of release 20.2, sync API tables are widely available. As of September 2022, the following 39 Exact Online tables are available as fast incremental tables:
- AccountsIncremental
- AddressesIncremental
- ContactsIncremental
- DocumentAttachmentFilesIncremental
- DocumentAttachmentsIncremental
- DocumentsIncremental
- GLAccountsIncremental
- GLClassificationsIncremental
- GoodsDeliveriesIncremental
- GoodsDeliveryLinesIncremental
- ItemsIncremental
- ItemWarehousesIncremental
- PaymentTermsIncremental
- ProjectPlanningsIncremental
- ProjectsIncremental
- ProjectWBSIncremental
- PurchaseOrderLinesIncremental
- QuotationLinesIncremental
- SalesInvoiceLinesIncremental
- SalesItemPricesIncremental
- SalesOrderLinesIncremental
- SalesOrderLinesV2Incremental
- SalesOrdersV2Incremental
- SalesPriceListVolumeDiscountsIncremental
- SerialBatchNumbersIncremental
- StockPositionsIncremental
- StockSerialBatchNumbersIncremental
- StorageLocationStockPositionsIncremental
- SubscriptionLinesIncremental
- SubscriptionsIncremental
- TimeCostTransactionsIncremental
- TransactionLinesIncremental
- CostTransactionsIncremental
- PjtTimeTransactionsIncremental
- PurchaseOrdersIncremental
- QuotationsIncremental
- SalesInvoicesIncremental
- SalesOrdersIncremental
- TransactionsIncremental
Local Storage
Invantive SQL provides the ability to maintain data in local caches. This is done largely automatically. The sync API tables require long-term storage; the data can easily be reconstructed from Exact Online, but updating for large companies with millions of entries per year takes a lot of time. The required data is stored in the “Incremental Cache” after encryption. The default location of this is %USERPROFILE%invantiveincdata. For web products, the same structure applies as for other local caches. The default location can be modified via the environment variable INVANTIVE_CONFIGURATION_INCREMENTAL_DATA_FOLDER. The contents of this folder look approximately as follows:
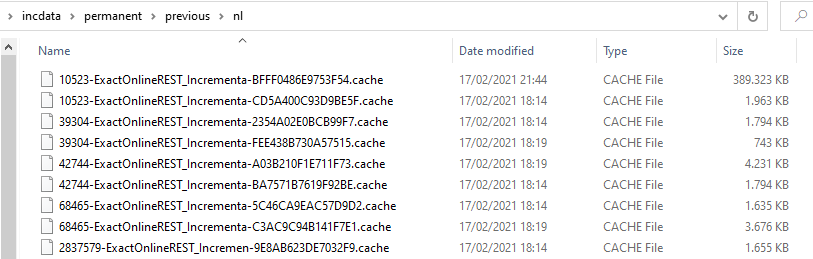
In case of problems, the contents of the incdata folder can be deleted. Make sure that Invantive SQL products are closed at that time. The Invantive SQL engine will automatically rebuild the content.
So what are the Exact Online Sync* tables?
Within Invantive SQL, both tables starting with Sync such as SyncItems and tables ending in Incremental such as ItemsIncremental are visible. What is the difference? They both contain the same rows.
The Sync tables are based on the Exact Online sync APIs like SyncItems is based on Sync/Logistics/Items. The Sync tables allow you to retrieve all mutations starting from a certain value for Timestamp. All rows are retrieved if no value for Timestamp is specified; this takes about 1 API call per 1,000 rows.
Using the Sync tables is not recommended unless one wants to write their own full logic in, for example, Invantive PSQL for combining mutations and limiting API calls. Instead, we recommend using the Incremental tables.
The Incremental tables build on Exact Online’s Sync APIs and hide all the complexity and numerous pitfalls when using the sync APIs. They typically internally use (after initial use) 2 API calls at Exact Online, regardless of the number of rows:
- a call to the associated
SyncExact Online REST API to retrieve all changes since the last time, and - a call to the Deleted API of Exact Online to retrieve all deleted rows.
This information is combined with the results from the previous time into a new result. Especially with large numbers of rows, this is significantly faster and easier than using the Sync APIs directly.
What about the Exact Online Webhooks?
For smaller numbers of companies, we expect that the use of webhooks will seriously decrease within a few months due to the new features. For larger numbers of companies, it is expected that replacing mutation messages in Data Replicator with sync APIs will only be implemented in the large environments in the second half of this year.
Invantive SQL in combination with Invantive Data Replicator is a high-end solution for data replication and synchronization with Exact Online. Data Replicator is suitable up to data volumes of several terabytes. This data replication software is and will remain the recommended choice for environments with a thousand or more Exact Online companies and on Exact Online the advice remains to continue using webhooks for trickle loading for the time being.
For near real-time event triggering such as marketing events, Exact Online webhooks will remain in use. Such messages can be managed via the Message Bus forms of Invantive Cloud.
Automatic Reload/Deletions.
On July 2, 2021 it was detected that deletions in Exact Online’s Deleted API are kept for a maximum of 2 months. The completeness of data is compromised if no refresh is done for more than 2 months for releases up to 20.1.437. It is recommended to update history more often than once a month.
As of release 20.1.437, the behavior of the *Incremental tables has changed. If the table has not been updated for 50 days, the table will be fully reloaded. This period can be set via max-age-sync-last-unused-days:
Maximum age in days of the last download for the *Incremental tables when it has not been refreshed, before being obsoleted and reloaded.
In addition, it has become possible to have the content completely forgotten via max-age-sync-initial-days after an adjustable number of days that defaults to 90 days:
Maximum age in days of the initial download for the *Incremental tables before being obsoleted and reloaded.