Op Invantive Cloud mag een query niet langer duren dan maximaal 180 seconden; anders wordt hij automatisch afgebroken met een 503. De SQL lukt wel, dus op zich gaat het redelijk vlot.
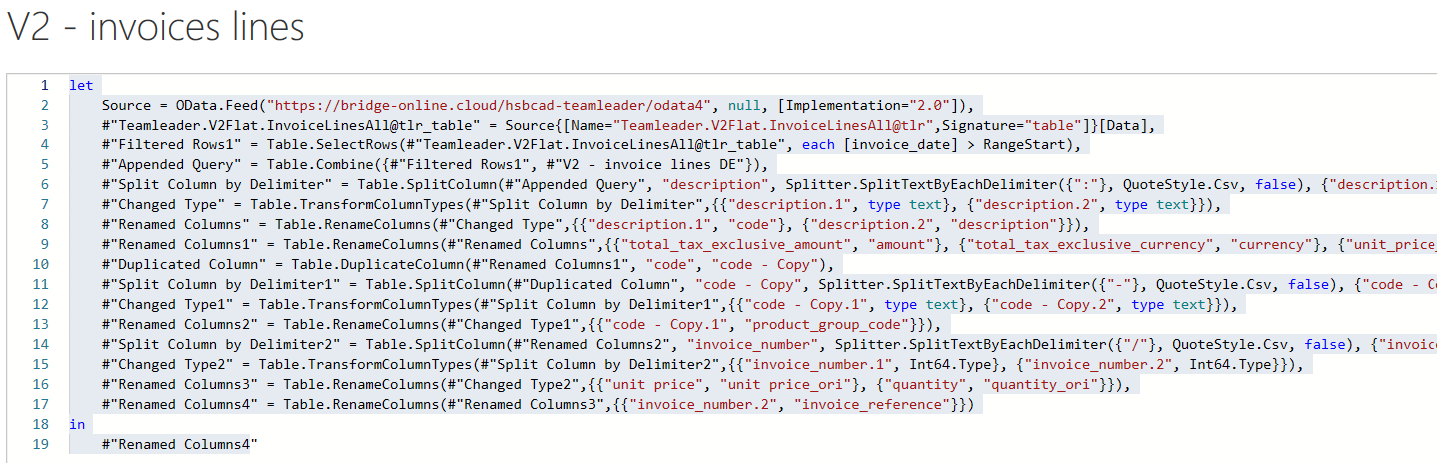
Advies is om bij where-clauses met een datum niet te vertrouwen op impliciete datatypeconversie. Beter is schrijven als bijvoorbeeld:
select *
from Teamleader.V2Flat.InvoiceLinesAll
where invoice_date > to_date('20201231', 'YYYYMMDD')
Dit voorkomt automatische datatypeconversie en daardoor vaak een beroerde performance.
Op Invantive Bridge Online begrijp ik dat een time-out geregistreerd wordt. Dit is nieuw gedrag; voorheen werd de download wel door bijvoorbeeld de Power BI Service afgebroken, maar dit werd niet zichtbaar gemaakt in Bridge Online Monitoring. Voor meer achtergrond zie Power BI downloads vanuit Twinfield, Exact Online en anderen vlot afbreken
In de Bridge Online Monitoring is meestal meer achtergrondinformatie zichtbaar. Daarom een aantal vragen:
Liepen er gelijktijdig meerdere maar verschillende requests binnen hetzelfde abonnement? Elke abonnementsvorm heeft een eigen limiet qua aantal gelijktijdige verzoeken (meestal 4). Elk volgend request wordt geparkeerd tot er een slot vrij is.
Liepen er gelijktijdig meerdere requests voor dezelfde data met hetzelfde filter? Zo ja, dan wordt elk gelijkluidend request geparkeerd totdat de eerst gestarte klaar is. Alle wachtenden retourneren dan de gegevens uit cache.
Om hoeveel rijen gaat het? Bij views uit de *Flat-reeks is de normale responsetijd per 100 rijen 4 minuten. De Teamleader API’s zijn niet echt geschikt voor grote volumes inclusief details.
Is er selectief gefilterd en is dat filter ook zichtbaar in de Bridge Online Monitoring bij de SQL-query?
Bedankt voor het advies bij de where-clauses; helaas heb je dit bij PowerBI niet zelf onder controle.
Antwoord op je vragen:
Liepen er gelijktijdig meerdere maar verschillende requests binnen hetzelfde abonnement? Elke abonnementsvorm heeft een eigen limiet qua aantal gelijktijdige verzoeken (meestal 4). Elk volgend request wordt geparkeerd tot er een slot vrij is. Dat wordt ook bevestigd in de monitoring.
A: wanneer je een “refresh” uitvoert in PowerBI heb ik de indruk dat alle requests in parallel gelanceerd worden maar in series uitgevoerd worden.
Liepen er gelijktijdig meerdere requests voor dezelfde data met hetzelfde filter? Zo ja, dan wordt elk gelijkluidend request geparkeerd totdat de eerst gestarte klaar is. Alle wachtenden retourneren dan de gegevens uit cache.
A: nee.
Om hoeveel rijen gaat het? Bij views uit de *Flat -reeks is de normale responsetijd per 100 rijen 4 minuten. De Teamleader API’s zijn niet echt geschikt voor grote volumes inclusief details.
A: het gaat om ongeveer 3.000 rijen en de responstijd is ongeveer 20 minuten. MAAR: telkens als ik de query uitvoer MET filter wordt er automatisch dezelfde query uitgevoerd ZONDER filter. En dan praten we over >15.000 rijen. Het binnenhalen van deze gegevens duurt ongeveer 1 uur. En helaas stopt de eerste query pas na het uitvoeren van de tweede query. Ik heb hierover eerder al een topic gepost.
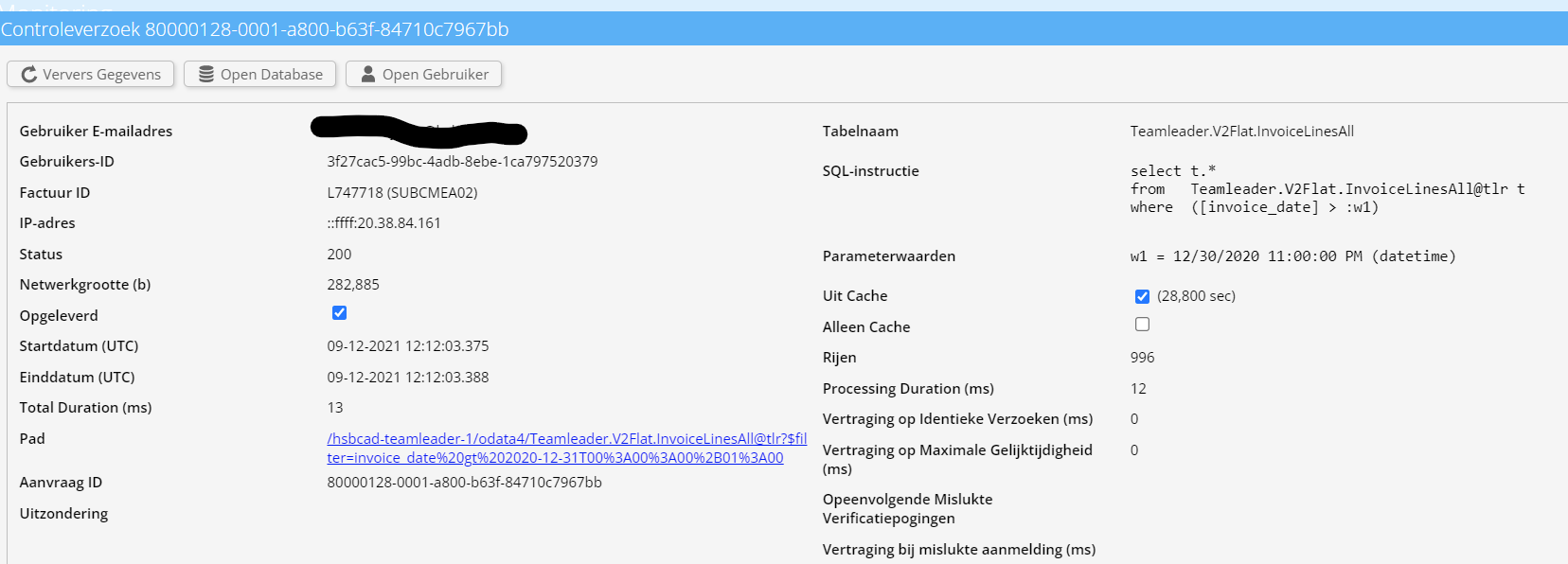
Is er selectief gefilterd en is dat filter ook zichtbaar in de Bridge Online Monitoring bij de SQL-query?
A: ja.
Printscreen van de monitoring - door het feit dat het opladen afgebroken wordt is er geen volledige logging.
Query 1 - Op TeamLeader met parameter start op 12:41:08
Correctie op eerder bericht: het lukt ook niet om de query uit te voeren vanuit de Invantive Cloud (vermoedelijk gebruikte de vorige query nog de cache). Als je vb. een bijkomende “where-clause” toevoegt of de “limit” verhoogd, dan krijg je na een aantal minuten een HTTP 504-fout.
Power BI zal inderdaad tegenwoordig verzoeken parallel afvuren met bijvoorbeeld 8 tegelijk. De Invantive Bridge Online zal dit verder beperken tot bijvoorbeeld 4 parallelle downloads.
15.000 factuurregels via V2Flat binnenhalen is tenminste een orde van grootte langzamere query dan de reguliere Teamleaderomgeving.
Ik begrijp dat de filterstap niet altijd doorkomt, waardoor er soms wel en soms zonder filter op invoice_date gewerkt wordt, terwijl dat wel kan.
Eerste advies is te proberen de filterstap in Power BI zo vorm te geven dat hij altijd doorkomt dankzij Power BI’s query-folding. De beste aanpak is om de filterstap direct na de download te zetten.
Controleer ook dat er niet nog andere datasets in het Power BI rapport zitten die toevallig los van elkaar dezelfde Teamleader data ophalen. Power BI voegt gelijke samenvoegbare queries helaas niet automatisch samen. Ook queries die sterk gelijkend zijn en samenvoegbaar worden helaas niet automatisch samengevoegd. Dat is handwerk. Vaak is met een dataset op PowerBI.com al veel te bereiken.
Het is te overwegen om de OData-feedstap te vervangen door een stap die de data in 1x ophaalt. Dat kan mogelijkerwijs met M zelf en anders via bijvoorbeeld Invantive App Online. Beiden vereisen wel wat medior programmeerervaring.
Laatste optie is gezien de omvang van de Teamleaderomgeving de stap naar Power BI Service of Azure Data Factory. Vooral met de laatste kan gemakkelijk het OData-request nauwkeuriger gestuurd worden. Zie voor een korte introductie:
Opnieuw bedankt voor de adviezen. Ik neem ze in overweging; alleen vereisen die tijd om te implementeren.
En er is nog geen verklaring waarom het binnenhalen van de data van de ene op de andere dag niet meer lukt. OK, het ophalen van de data was niet supersnel maar de verwerkingstijd was heel constant. Bij gelijkaardige voorvallen uit het verleden met andere tabellen lag de oorzaak steeds bij de API van Teamleader. Kan deze piste aub ook bekeken worden ? Ik zal wel aandringen bij TeamLeader maar ze gaan verwachten dat jullie een ticket aanmaken. Alvast bedankt.
Bij gebrek aan een aanwijsbare storing kunnen we vanuit het abonnement hierin niks betekenen. De omvang en gebruik van de Teamleaderomgeving is dusdanig dat het niet te verwachten is dat Teamleader als pakket hiervoor de optimale oplossing is.
Het ophalen van grote aantallen detailrecords vereist op de Teamleader API helaas veel aandacht omdat enkel puntqueries mogelijk zijn.
Mocht een bug of onhandig gebruik aan te wijzen zijn dan zullen we die uiteraard oppakken. Voeg eventuele meldingen uit Systeemberichten die hierop wijzen dan toe via knop “Antwoorden”.
Mocht de vereiste tijd een probleem zijn, dan is het raadzaam om eventueel een consultant te betrekken om een analyse te maken van de verbeteringsmogelijkheden en/of alternatieve producten, en die te laten uitvoeren.
Bijkomende informatie: omwille van historische redenen hebben we twee TeamLeader-omgevingen:
Teamleader 1 bevat alle facturen van onze BE, NL en rest van de wereld klanten,
Teamleader alle facturen van DE en IT klanten.
Vandaar de twee OData connecties die via de Invantive Cloud lopen.
Qua omvang zijn beide Teamleaderomgevingen vergelijkbaar; de set-up is identiek. Het “time-out” probleem stelt zich enkel met Teamleader; de gegevens van Teamleader komen zonder problemen binnen. Dus er moet m.i. toch iets zijn dat een fout triggert bij het binnenhalen van de gegevens uit Teamleader.
Ik kan me voorstellen dat lastig is om kennis te vinden voor een complexe Teamleaderomgeving. Mocht niet lukken in de markt, dan is eventueel optie om een korte analyse door Invantive te laten uitvoeren. Hiervoor is delegatie nodig, maar helaas kunnen we niks toezeggen. Op gegeven moment is een pakket gewoon overvraagd (en dat kan een jaar later weer normaal zijn of nog steeds een issue).
Als de twee Teamleader-omgevingen vergelijkbaar zijn qua omvang, dan kunnen de downloads eventueel vergeleken worden: draai op beide omgevingen tegelijk de URL, niet vanuit Power BI, maar met bijvoorbeeld curl (zie voor voorbeeld het artikel “Pre-load data in OData-cache to avoid Power BI timeouts” of Hoe gebruik ik curl om een Invantive Cloud OData4-verzoek uit te voeren?). Dit haalt in ieder geval Power BI als factor uit de vergelijking. In het scherm “Sessie I/O’s” (erg langzaam helaas) zijn daarna de prestaties te vergelijken.
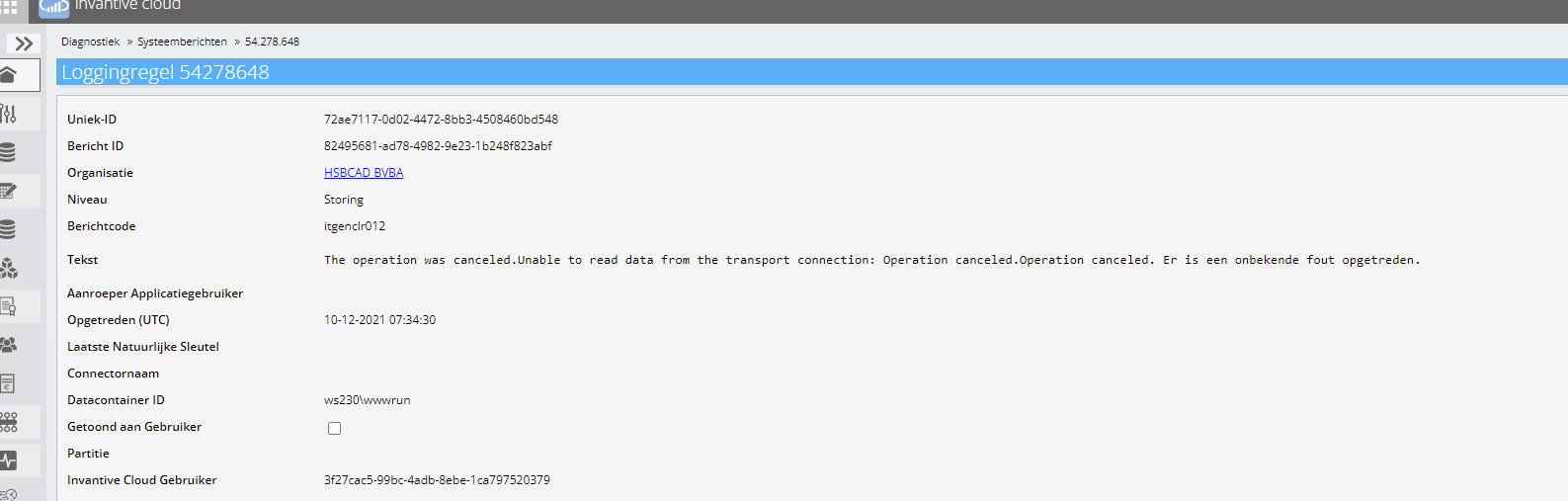
M.b.t. de melding:
itgenclr012
The operation was canceled.
Unable to read data from the transport connection:
Operation canceled.
Operation canceled.
Er is een onbekende fout opgetreden.
Deze verwijst naar een verbroken netwerkverbinding (SocketException) bij het ophalen van sessie I/O’s bij Invantive Data Guard (dat is voor gebruikers niet te achterhalen). Sessie I/O’s is erg langzaam; het volume aan verwerkte gegevens is sneller gegroeid dan we verwacht hadden. Deze structuur is terug te vinden op Invantive Cloud Structure.
Als ik de uitleg goed begrijp dan is de wordt de connectie tussen de Azure Data Factory (ADF) en Teamleader op dezelfde manier opgebouwd als dit nu het geval is tussen Power BI en TeamLeader (stap 2 in de procedure). M.a.w. de connectie verloopt over de TeamLeader API.
Welk voordeel levert dit op ?
Het enige wat ik kan bedenken is dat de “views” (zoals de “InvoiceLinesAll”) in ADF kunnen aangemaakt worden en daardoor misschien performanter kunnen bevraagd worden. Is dit een correcte aanname?
En hoe wordt de data tussen ADF en TeamLeader gesynchroniseerd?
Het gebruik van Azure Data Factory als ETL-tool heeft voor deze toepassing twee voordelen:
De data kan ergens opgeslagen en bijgewerkt worden, waardoor optimalisaties mogelijk worden zoals het bijladen. Bijladen (incrementeel laden) in Power BI is nog niet optimaal geregeld.
Azure Data Factory is veel flexibeler en beter te controleren dan Power BI bij het realiseren van performanceverbeteringen.
Een aantal gerelateerde eerdere vragen over de combinatie Teamleader met Azure Data Factory die ik zo snel kan vinden:
Daarnaast is op de volgende pagina een setup-plan te vinden:
Het gebruik van Azure Data Factory wordt door Microsoft op verschillende websites uitgelegd en gedocumenteerd. De synchronisatie kan via Azure Data Factory ingeregeld worden. Sommigen doen dit vrij frequent en incrementeel, anderen halen de data 1x per dag op.
Update: via een (manuele) work-around lukt het me wel om de gegevens in blokken van 500 records in te lezen. Als ik het aantal records in een blok verhoog, krijg ik een “time-out”. Het aantal records waarbij ik een “time-out” krijg is arbitrair, soms lukt het met 1.000 records, soms krijg ik al een time-out bij 600 records. 500 records is een “veilige” grens.
Rest nu de vraag waar die “time-out” plots vandaan komt en waar hij veroorzaakt wordt.
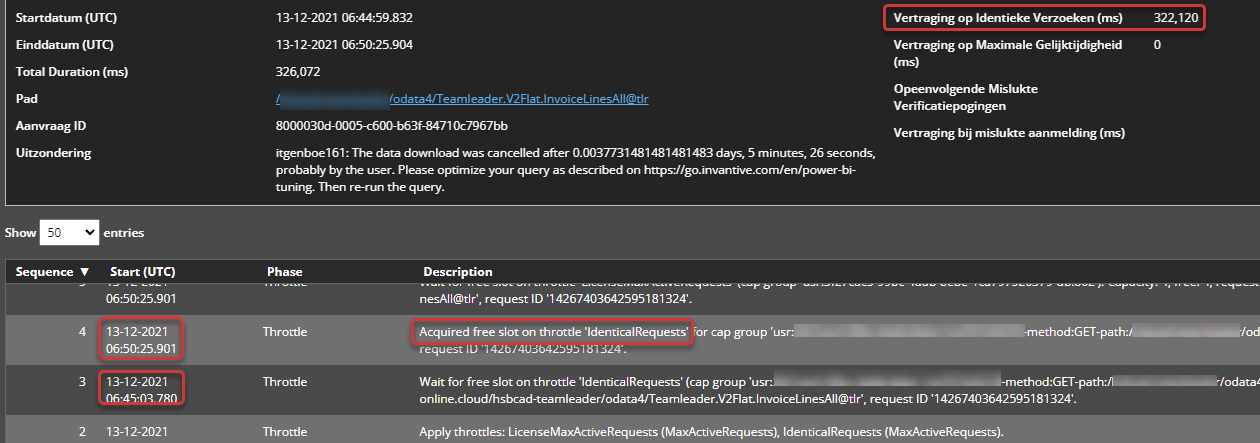
Error itgenboe161: The data download was cancelled after 0.0037731481481481483 days, 5 minutes, 26 seconds, probably by the user.
path:/hsbcad-teamleader/odata4/Teamleader.V2Flat.InvoiceLinesAll@tlr’ in 322,121 ms
De melding met code itgenboe161 en HTTP status 499 in Bridge Online Monitoring betekent dat de zijde die data ontvangt de verbinding heeft beëindigd door via HTTP een verzoek daartoe te sturen.
Op basis van het door ons opgezochte IP-adres is dat een server in Microsoft Azure.
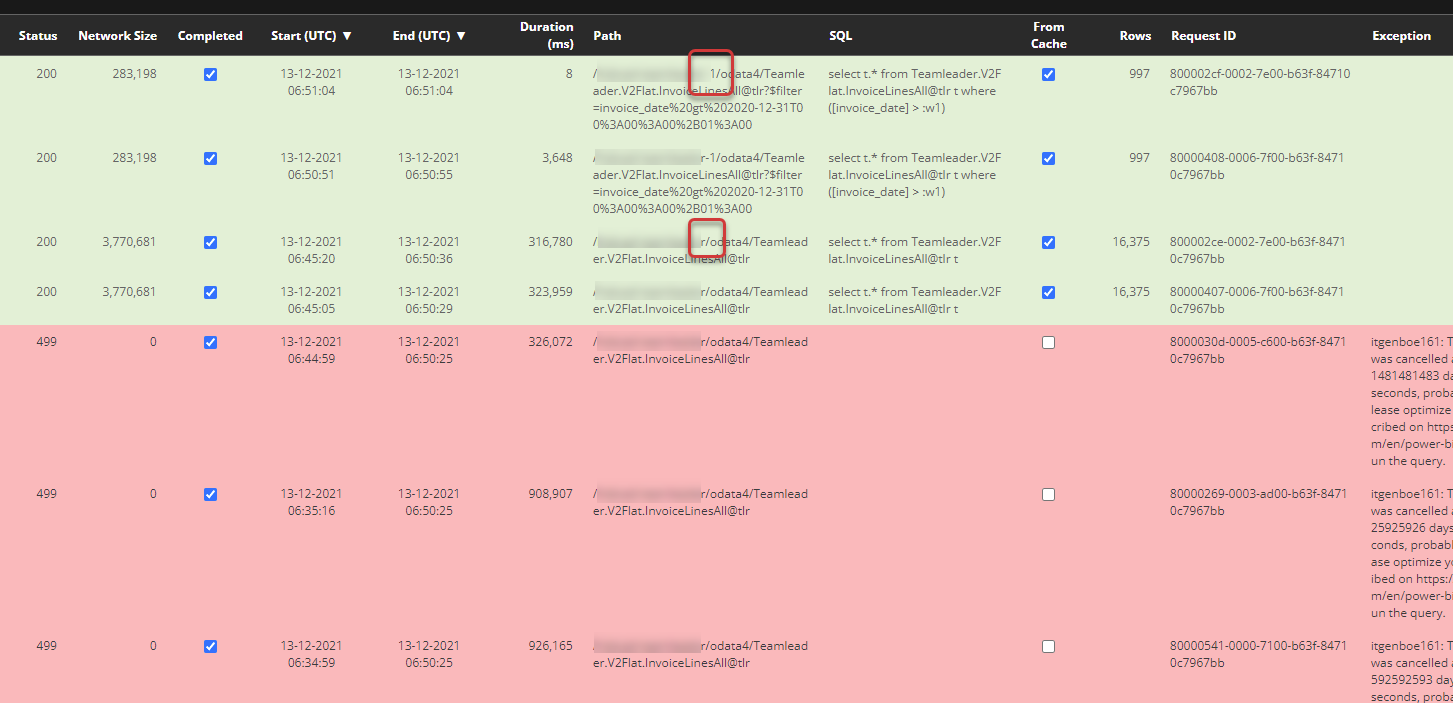
In de Bridge Online Monitoring is te zien dat op hetzelfde tijdstip meerdere downloads van dezelfde dataset waren aangevraagd. Dubbele downloads worden geparkeerd qua afhandeling totdat degene die het eerst gestart is klaar is. Dit is zichtbaar bij details:
Zodra het eerste verzoek teruggegeven werd, werden dubbele verzoeken blijkbaar grotendeels massaal door het aanvragende programma beëindigd (wat op zich een logische ontwerpkeuze kan zijn). Een aantal downloads zijn al afgerond voordat de beeindiging plaatsvindt. De oorspronkelijke download liep van 06:04:54 tot 06:50:06. Deze blokkeerde (terecht) enkele tientallen andere identieke downloads totdat hij klaar was.
In het algemeen raden we het gebruik van datasets aan om te voorkomen dat herhaaldelijk dezelfde gegevens opgehaald worden. Dit zorgt er voor dat de beschikbare slots voor parallelle downloads niet allemaal geblokkeerd raken door identieke verzoeken, waardoor de looptijden dramatisch omlaag kunnen gaan.
Indien toch nodig, dan is het mogelijk over te stappen op een abonnement met meer parallelle downloadslots dan 4.
Verder valt op dat er twee verschillende maar gelijkende downloads zijn:
eindigend in de URL op de letter ‘r’,
eindigend in de URL op het cijfer ‘1’.
Mogelijkerwijs betreft dit het verschil tussen de twee Teamleaderomgevingen. In dat geval kan het handig zijn om bij degene eindigend op ‘r’ ook een datumbereik mee te geven.
Deze vraag is automatisch gesloten na tenminste 2 weken inactiviteit nadat een mogelijk passend antwoord is gegeven. Het laatste gegeven antwoord is gemarkeerd als oplossing.
Gelieve een nieuwe vraag te stellen via een apart topic als het probleem opnieuw optreedt. Gelieve in de nieuwe vraag een link naar dit topic op te nemen door de URL er van in de tekst te plakken.